Connecting to a Dremio Enterprise Cluster
You can add a Dremio Enterprise cluster as a data source. Such a cluster is referred to as a data-source cluster.
Only Dremio Enterprise can serve as a data-source cluster. Using Dremio Cloud as a data-source cluster is not supported.
A data-source cluster gives you access to one or more data sources, such as Amazon S3, Hive, and Postgres, that are connected to the data-source cluster. You can use the connected Dremio cluster as any other supported data source. The data sources that are connected to the data-source cluster are represented as schemas. From a Sonar project, you can drill down into the schemas to see source datasets. You can then promote source datasets to tables, create Reflections and views on those tables, and views on the views, and so on.
Examples of Use Cases
-
You can connect to a Dremio Enterprise cluster from Dremio Cloud to reduce query latency. Suppose that your Dremio Cloud organization is in the US region and the cluster is in Japan, and that you have client applications in the US that query on data in both. Rather than require your client applications to send queries all the way to the cluster, you can connect to the cluster in Dremio Cloud and create Reflections of the data that the client applications need to query. Then, the clients can query Dremio Cloud directly, and the query planner can use the Reflections to satisfy their queries.
-
You can connect to more than one Dremio Enterprise cluster, join data across those clusters, and have that data available as views in Dremio Cloud. Client applications could then query the views, rather than perform the joins themselves.
-
Security: Instead of exposing all sources from your on-prem datacenter, you can connect those sources to the on-prem Dremio cluster and only expose the Dremio port to the cloud.
Example Configuration
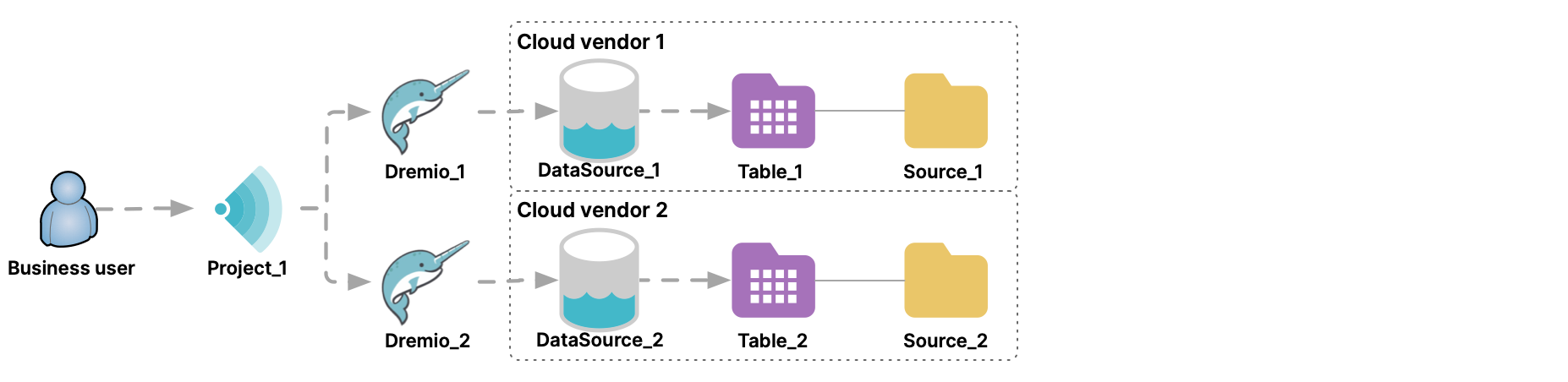
In this diagram, there are a Sonar project, Project_1, and a Dremio cluster, Dremio_1. Suppose that you wanted to access DataSource_2 from Project_1. To do so, you would add Dremio_1 as a data source to Project_1. In fact, you could add any number of Dremio Enterprise clusters as data sources.
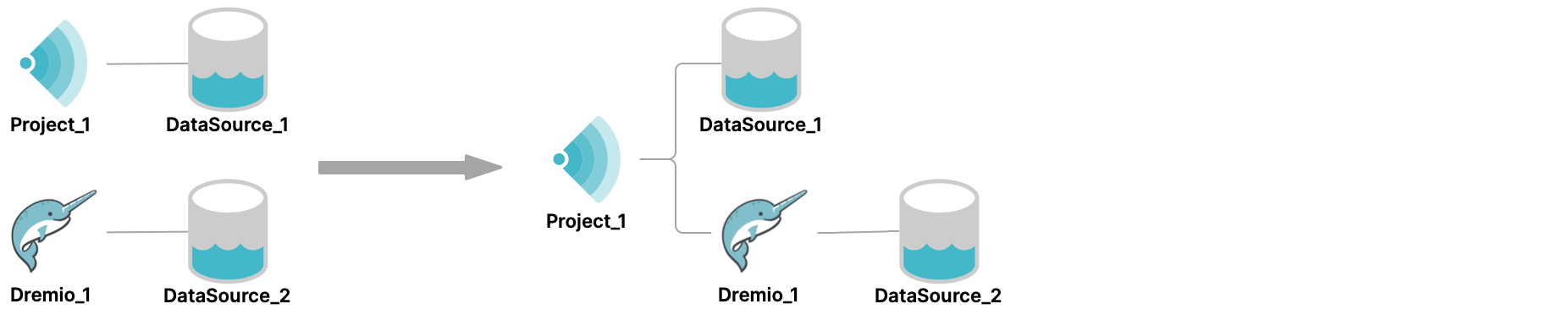
In the UI for Project_1, Dremio_1 is listed under Sources > Databases. If you were to select Dremio_1 there, you would see the folder DataSource_2. Double-clicking that folder would show a list of the folders or schemas in that data source.
An administrator can promote a table on a data source connected through a data-source cluster, just as it is possible to do on data source that is directly connected to a Sonar project. For example, an administrator promotes table DataSource_1.Table_1 from DataSource_1.Source_1 on the data source directly connected to Project_1, and also promotes table Dremio_1.DataSource_2.Table_2 from DataSource_2.Source_2 via the data-source cluster.
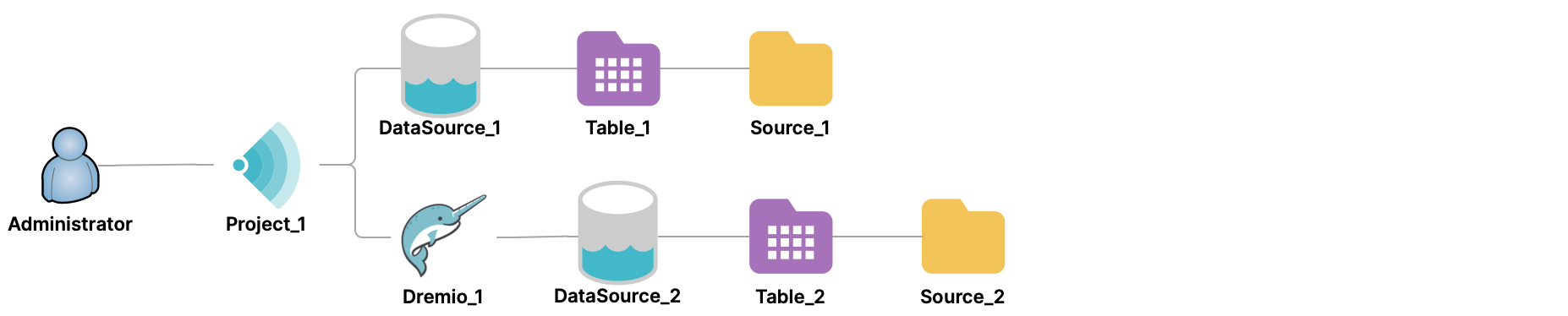
The administrator can then use the tables as any other table, by querying them, creating views on them, and creating Reflections on them.
If Project_1 were connected to two Dremio clusters, the administrator could promote tables on both. Then, business users could run queries and view reports that federated data across the two data-source clusters.
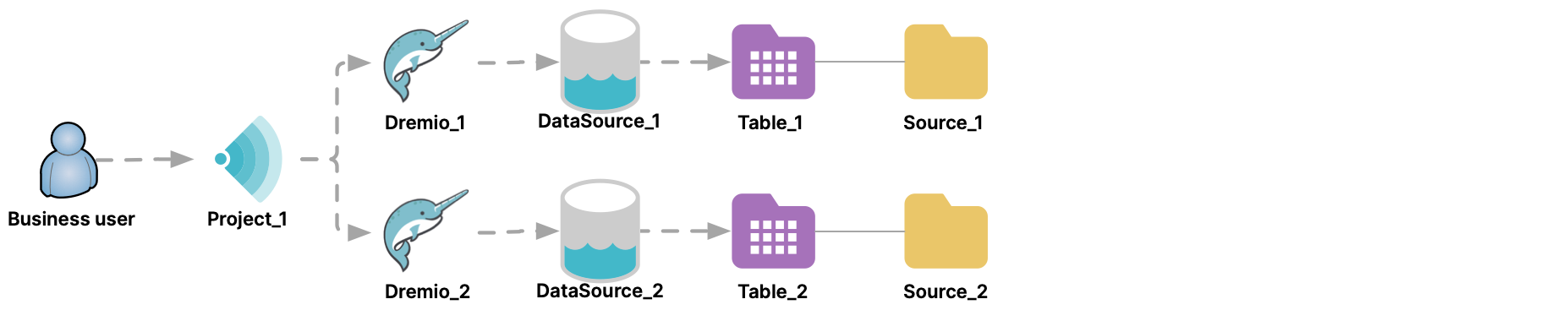
And while business users run queries through the Sonar project, other business users can continue running queries directly through a data-source cluster.
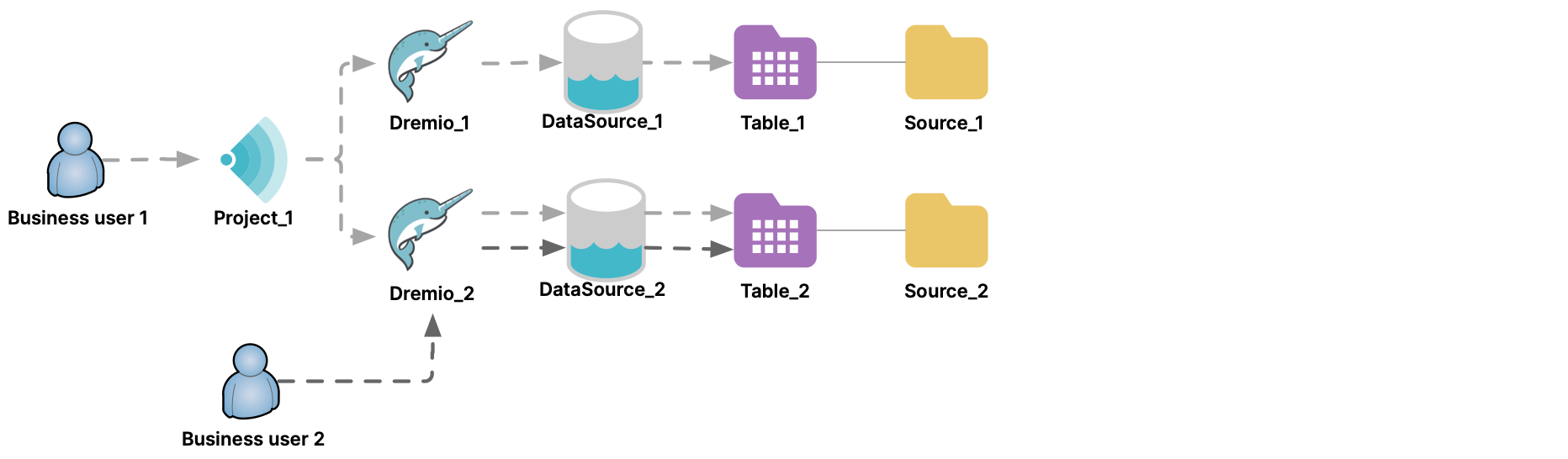
Querying across more than one region or more than one cloud vendor might increase query latency. Querying across cloud vendors also might result in egress charges from cloud vendors. For example, in this diagram DataSource_1 is using one cloud vendor, while DataSource_2 is using a different cloud vendor. Queries from Project_1 across Dremio_1 and Dremio_2 against those two data sources might incur egress charges from the cloud vendors.
Recommendation: Configure full TLS wire encryption on data-source clusters.
User Impersonation
When you connect a Sonar project to a data-source cluster, you provide the username and password of an account on the data-source cluster. By default, queries that run from the Sonar project against the data-source cluster run under the username of that account.
You can instead allow users running queries from the Sonar project to run them under their own usernames on the data-source cluster. For example, User 1 on the Sonar project Project_1 can run queries as User_1 on the data-source cluster. User_1 must have an account on the data-source cluster, and that account must use the same username. User impersonation (also known as Inbound Impersonation) must be set up on the data-source cluster. The policy for user impersonation would look like this:
Example policyALTER SYSTEM SET "exec.impersonation.inbound_policies"='[
{
"proxy_principals":{
"users":[
"User_1"
]
},
"target_principals":{
"users":[
"User_1"
]
}
}
]'
Prerequisites
- You must have a username and password for the account on a data-source cluster to use for connections from the Sonar project.
- The data-source clusters must all be at version 23.0 or later.
Configuring a Dremio Enterprise Cluster as a Source
-
In the bottom-left corner of the Datasets page, click Add Source.
-
Under Databases in the Add Data Source dialog, select Dremio.
noteSources containing a large number of files or tables may take longer to be added. During this time, the source name is grayed out and shows a spinner icon, indicating the source is being added. Once complete, the source becomes accessible.
General Options
- In the Name field, specify the name by which you want the data-source cluster to appear in the Databases section. The name cannot include the following special characters:
/,:,[, or]. - Under Connection, specify how you want to connect to the data-source cluster.
- Direct: Connect directly to a coordinator node of the cluster.
- ZooKeeper: Connect to an external ZooKeeper instance that is coordinating the nodes of the cluster.
- In the Host and Port field, specify the hostname or IP address, and the port number, of the coordinator node or ZooKeeper instance.
- If the data-source cluster is configured to use TLS for connections to it, select the Use SSL option.
- Under Authentication, specify the username and password for the Sonar project to use when connecting to the data-source cluster.
Advanced Options
On the Advanced Options page, you can set values for these non-required options:
| Option | Description |
|---|---|
| Maximum Idle Connections | The total number of connections allowed to be idle at a given time. The default maximum idle connections is 8. |
| Connection Idle Time | The amount of time (in seconds) allowed for a connection to remain idle before the connection is terminated. The default connection idle time is 60 seconds. |
| Query Timeout | The amount of time (in seconds) allowed to wait for the results of a query. If this time expires, the connection being used is returned to an idle state. |
| User Impersonation | Allows users to run queries on the data-source cluster under their own user IDs, not the user ID for the account used to authenticate with the data-source cluster. Inbound impersonation must be configured on the data-source cluster. |
Reflection Refresh Options
On the Reflection Refresh page, set the policy that controls how often Reflections are scheduled to be refreshed automatically, as well as the time limit after which Reflections expire and are removed.
| Option | Description |
|---|---|
| Never refresh | Select to prevent automatic Reflection refresh, default is to automatically refresh. |
| Refresh every | How often to refresh Reflections, specified in hours, days or weeks. This option is ignored if Never refresh is selected. |
| Never expire | Select to prevent Reflections from expiring, default is to automatically expire after the time limit below. |
| Expire after | The time limit after which Reflections expire and are removed from Dremio, specified in hours, days or weeks. This option is ignored if Never expire is selected. |
Metadata Options
On the Metadata page, you can configure settings to refresh metadata and handle datasets.
Dataset Handling
These are the optional Dataset Handling parameters.
| Parameter | Description |
|---|---|
| Remove dataset definitions if underlying data is unavailable | By default, Dremio removes dataset definitions if underlying data is unavailable. Useful when files are temporarily deleted and added back in the same location with new sets of files. |
Metadata Refresh
These are the optional Metadata Refresh parameters:
-
Dataset Discovery: The refresh interval for fetching top-level source object names such as databases and tables. Set the time interval using this parameter.
Parameter Description (Optional) Fetch every You can choose to set the frequency to fetch object names in minutes, hours, days, or weeks. The default frequency to fetch object names is 1 hour. -
Dataset Details: The metadata that Dremio needs for query planning such as information required for fields, types, shards, statistics, and locality. These are the parameters to fetch the dataset information.
Parameter Description Fetch mode You can choose to fetch only from queried datasets that are set by default. Dremio updates details for previously queried objects in a source. Fetching from all datasets is deprecated. Fetch every You can choose to set the frequency to fetch dataset details in minutes, hours, days, or weeks. The default frequency to fetch dataset details is 1 hour. Expire after You can choose to set the expiry time of dataset details in minutes, hours, days, or weeks. The default expiry time of dataset details is 3 hours.
Privileges
On the Privileges page, you can grant privileges to specific users or roles. See Access Control for additional information about user privileges.
- (Optional) For Privileges, enter the user name or role name that you want to grant access to and click the Add to Privileges button. The added user or role is displayed in the Users table.
- (Optional) For the users or roles in the Users table, toggle the green checkmark for each privilege you want to grant on the Dremio source that is being created.
- Click Save after setting the configuration.
Editing a Dremio Source
To edit a Dremio source:
-
On the Datasets page, click External Sources at the bottom-left of the page. A list of sources is displayed.
-
Hover over the source and click the Ellipsis (...) that appears next to the source. From the list of actions, click Settings.
Alternatively, you can click ![]() , which appears next to the source:
, which appears next to the source:
-
In the Source Settings dialog, you cannot edit the name. Editing other parameters is optional. For parameters and advanced options, see Configuring a Dremio Enterprise Cluster as a Source.
-
Click Save.
Removing a Dremio Source
To remove a Dremio source, perform these steps:
-
On the Datasets page, click External Sources at the bottom-left of the page. A list of sources is displayed.
-
Hover over the source and click the Ellipsis (...) that appears next to the source.
-
From the list of actions, click Remove Source. Confirm that you want to remove the source.
cautionRemoving a source causes all downstream views dependent on objects in this source to break.
noteSources containing a large number of files or tables may take longer to be removed. During this time, the source name is grayed out and shows a spinner icon, indicating the source is being removed. Once complete, the source disappears.
Predicate Pushdowns
Sonar projects offload these operations to data-source clusters. Data-source cluster either process these operations or offload them to their connected data sources.
&&, ||, !, AND, OR
+, -, /, *, %
<=, <, >, >=, =, <>, !=
ABS
ADD_MONTHS
AVG
BETWEEN
CASE
CAST
CEIL
CEILING
CHARACTER_LENGTH
CHAR_LENGTH
COALESCE
CONCAT
CONTAINS
COUNT
COUNT_DISTINCT
COUNT_DISTINCT_MULTI
COUNT_FUNCTIONS
COUNT_MULTI
COUNT_STAR
CURRENT_DATE
CURRENT_TIMESTAMP
DATE_ADD
DATE_DIFF
DATE_SUB
DATE_TRUNC
DATE_TRUNC_DAY
DATE_TRUNC_HOUR
DATE_TRUNC_MINUTE
DATE_TRUNC_MONTH
DATE_TRUNC_QUARTER
DATE_TRUNC_WEEK
DATE_TRUNC_YEAR
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FLATTEN
FLOOR
ILIKE
IN
IS DISTINCT FROM
IS NOT DISTINCT FROM
IS NOT NULL
IS NULL
LAST_DAY
LCASE
LEFT
LENGTH
LIKE
LOCATE
LOWER
LPAD
LTRIM
MAX
MEDIAN
MIN
MOD
NEXT_DAY
NOT
NVL
PERCENTILE_CONT
PERCENTILE_DISC
PERCENT_RANK
POSITION
REGEXP_LIKE
REPLACE
REVERSE
RIGHT
ROUND
RPAD
RTRIM
SIGN
SQRT
STDDEV
STDDEV_POP
STDDEV_SAMP
SUBSTR
SUBSTRING
SUM
TO_CHAR
TO_DATE
TRIM
TRUNC
TRUNCATE
UCASE
UPPER
VAR_POP
VAR_SAMP
Limitation
You cannot query columns that use complex data types, such as LIST, STRUCT, and MAP. Columns of complex data types do not appear in result sets.