Querying Your Data
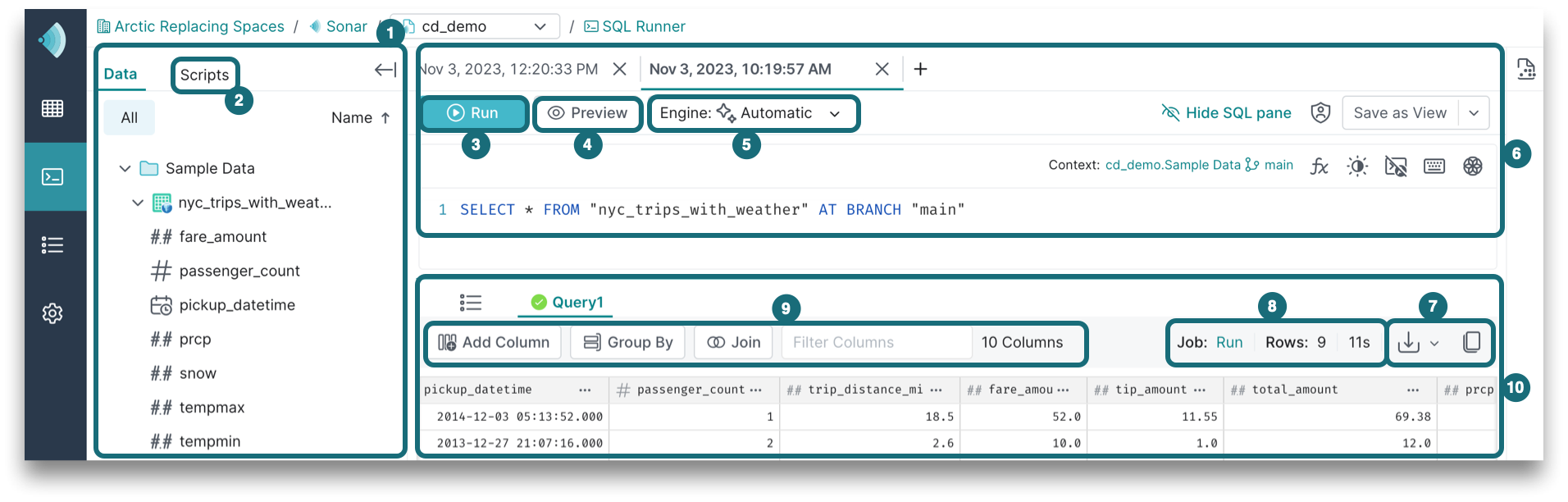
The SQL Runner is where you run queries on your datasets and get results. To navigate to the SQL Runner, click ![]() in the side navigation bar. The main components of the SQL Runner are highlighted below:
in the side navigation bar. The main components of the SQL Runner are highlighted below:
Dremio's query engine intentionally ignores any file or folder if the filename or folder name starts with a period (“.”) or an underscore (“_”).
1. Data
The Data panel is used to explore your data catalog, which includes sources, tables, and views.
To add a dataset into the SQL editor, go to the data source. Use the left > caret to expand the source view. Locate the dataset that you would like to use within the query. Click the + button or drag and drop the data into the SQL editor.
2. Scripts
You can save your SQL as a script if you have drafts or SQL statements that you run frequently. Each saved script has a name, when the script was created or modified, and the context that was set for the editor.
In the Scripts panel, you can:
Open a script in the SQL editor
Rename a script
Delete a script
Share a script by granting privileges
Search your set of scripts by name
Sort scripts by name or date
noteWhen viewing a script, the script ID is included in the page URL, so you can copy and share the URL with another user in your organization. The user must have
VIEWprivileges on the script that you are sharing.
3. Run Mode
Running the query routes it to the selected engine and returns the complete result set. Learn more about engine autoscaling.
Dremio's query engine intentionally ignores any file or folder if the filename or folder name starts with a period (“.”) or an underscore (“_”).
If the engine has zero replicas running at the time of the query run, the startup time will take about two minutes.
Sometimes COUNT(*) and SELECT query results do not match because the result of queries run in the Dremio app has a threshold of one million. Depending on the number of threads (minor fragments) and how data is distributed among those threads, Dremio could truncate results before reaching the threshold. Each individual thread stops processing after returning a number of records equal to threshold/# of threads. For example, a query runs with 10 threads and should return 800,000 records, but one of the threads is responsible for 400,000 records. The per-thread threshold is 100,000, so that thread will only return 100,000 records and you will only see 500,000 records in the output. When results are truncated, the Dremio app will display a warning that the results are not complete and users can execute the query using JDBC/ODBC to get complete results.
4. Preview Mode
Executing a preview returns a subset of rows in the result set. Like the run mode, running the preview job will route the query to the selected engine, although the preview mode runs a subset of your results in less time.
5. Engine Selector
Use the Engine dropdown to specify an engine for query execution. To choose your engine, click the Engine dropdown and select an engine from the dropdown. By default, Automatic is selected, which will use engine routing rules at runtime to route the query to the appropriate engine.
6. SQL Editor
The SQL editor is where you create and edit queries to get insight from your data. For more information on supported SQL, see the SQL Reference.
In the SQL editor, you can:
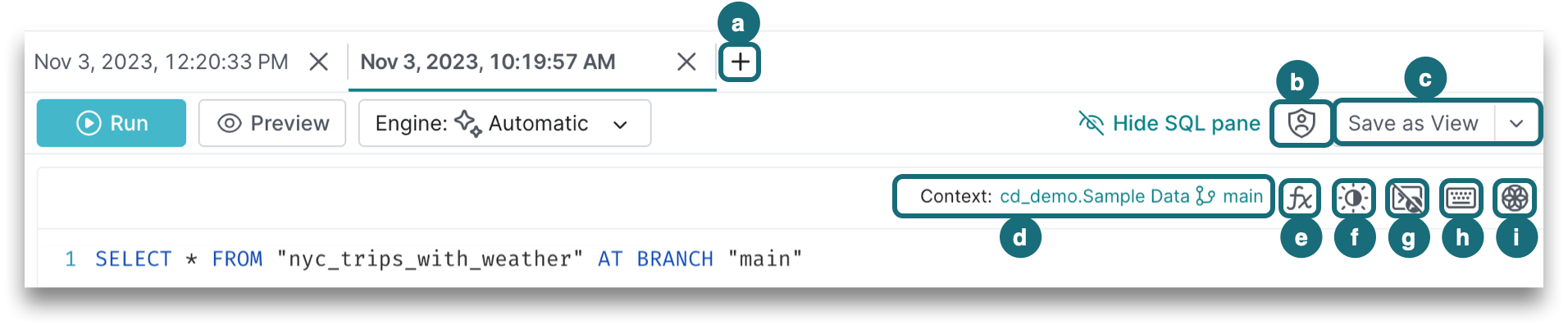
a. Create a new tab by clicking + next to the other tabs. Because a tab is defined by a session, a new tab is automatically saved as a script and named as the date and time that the session was created, such as Nov 3, 2023, 10:19:57 AM.
b. Grant script privileges to share a saved script with others in your organization.
c. Save your SQL as a script or as a view. You can save a script even if there are syntax errors. Saving a new view requires valid syntax, and there can be only one SQL statement in the editor. Clicking the Save as View option opens a new window for the details page rather than updating the current window.
d. Set a Context for your session to run queries without having to fully qualify the referenced objects. This is useful for running queries against Arctic catalog references (e.g., branches and tags). For more information, see Connecting Dremio Sonar to Arctic.
e. Use fx to see a list of functions supported by Dremio along with a short description and syntax of each function. Click + or drag and drop the function template into the SQL editor.
f. Toggle the dark/light mode to change the theme of the SQL editor.
g. Enable autocomplete to receive suggestions for SQL keywords, catalog objects, and functions while you are constructing SQL statements. Suggestions depend on the context set in the SQL Runner. The autocomplete feature can also be enabled or disabled for all your users by navigating to Project Settings > Preferences > SQL Autocomplete.
h. Use the keyboard to reference any shortcuts. You can format your SQL using the Format Query shortcut as long as the syntax is valid.
i. Open Text-to-SQL in a side panel within the SQL editor and uses Generative AI to translate your text into a SQL query. To enable this feature and learn more about Generative AI Capabilities, see Text-to-SQL experience.
To close all tabs besides the active tab, hover over the active tab name, click ![]() , and select Close Others.
, and select Close Others.
Syntax Error Highlighting
Before you run a query, make sure to fix any syntax errors that have been detected in your query.
The SQL editor automatically checks for syntax errors, and every detected error is marked with a red wavy underline. If you hover over the error, you’ll see a message stating whether the error is the result of a token that is missing, unexpected, unrecognized, or extraneous in the query.
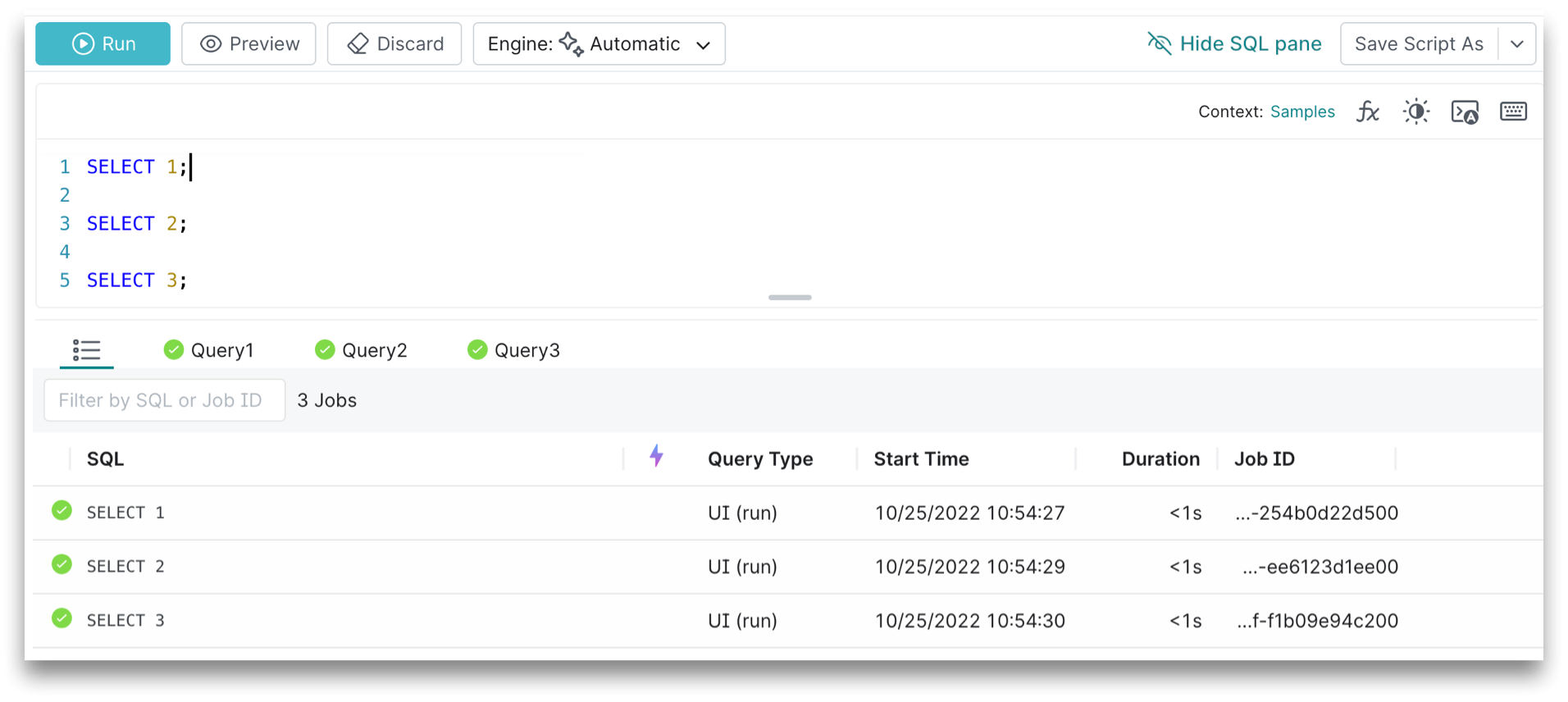
Running Multiple Queries
You can run multiple queries in the SQL editor by using a semicolon to separate each statement. To run all of the queries in the SQL editor, simply click Run. The results of each query will be shown in the same order that the queries are constructed:
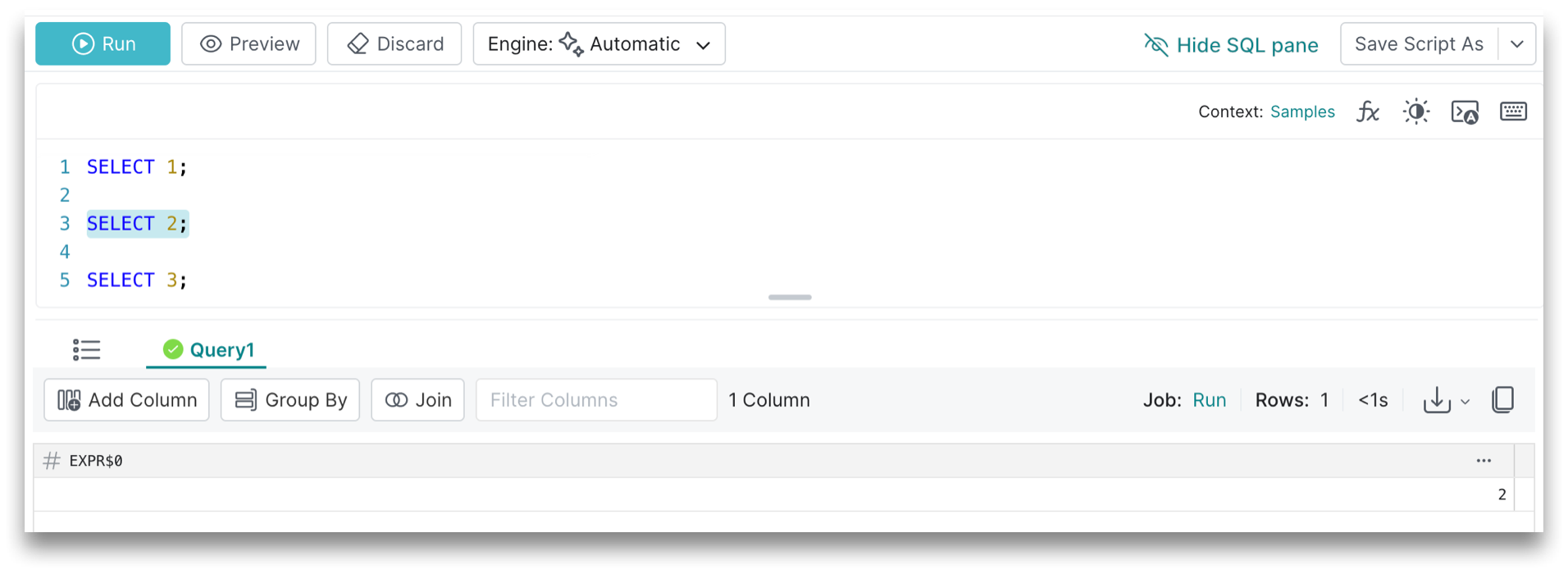
When you have multiple queries, you can also select a subset to run. If you select one or more queries and then click Run, only the selected queries will run accordingly, as shown below:
7. Result Set Actions
Above the top-right corner of the result set, you will find these actions:
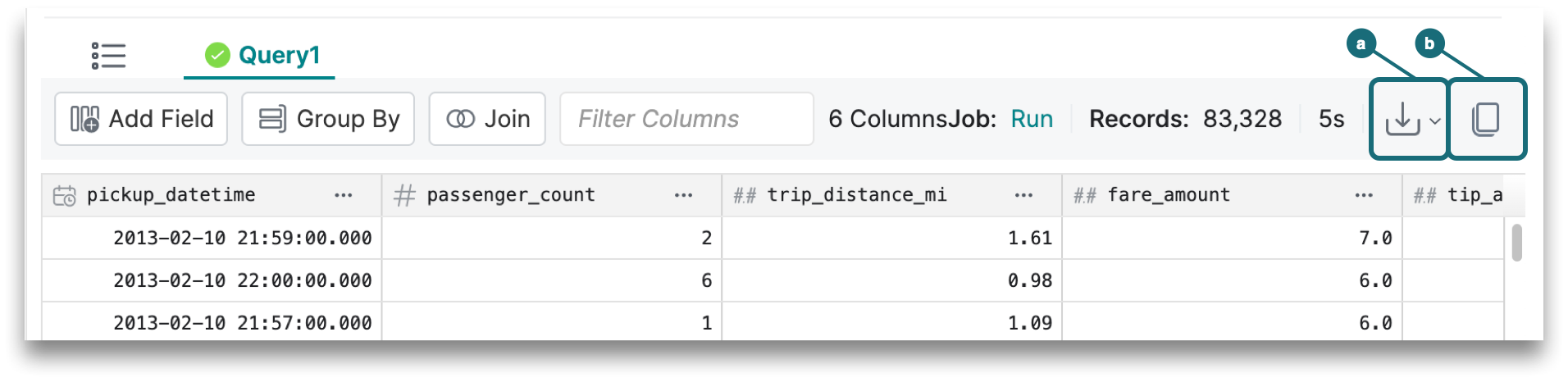
a. Download the result set as a JSON, CSV, or Parquet file.
b. Copy result set to a clipboard. If the result set is too large, then download the table content to get the complete results.
- The option to download as a CSV file is not available if the result set includes one or more columns that have complex datatypes (i.e., a union, map, or array). Column headers for the results table indicate complex types with this icon:

- The download process runs a CREATE TABLE AS SELECT (CTAS) command, which is why compute resources are required.
The download and copy results features can be enabled or disabled for a project by navigating to Project Settings > Preferences > Copy or download results. Disabling this in a project will prevent all users from downloading and copying results from the project.
8. Execution State
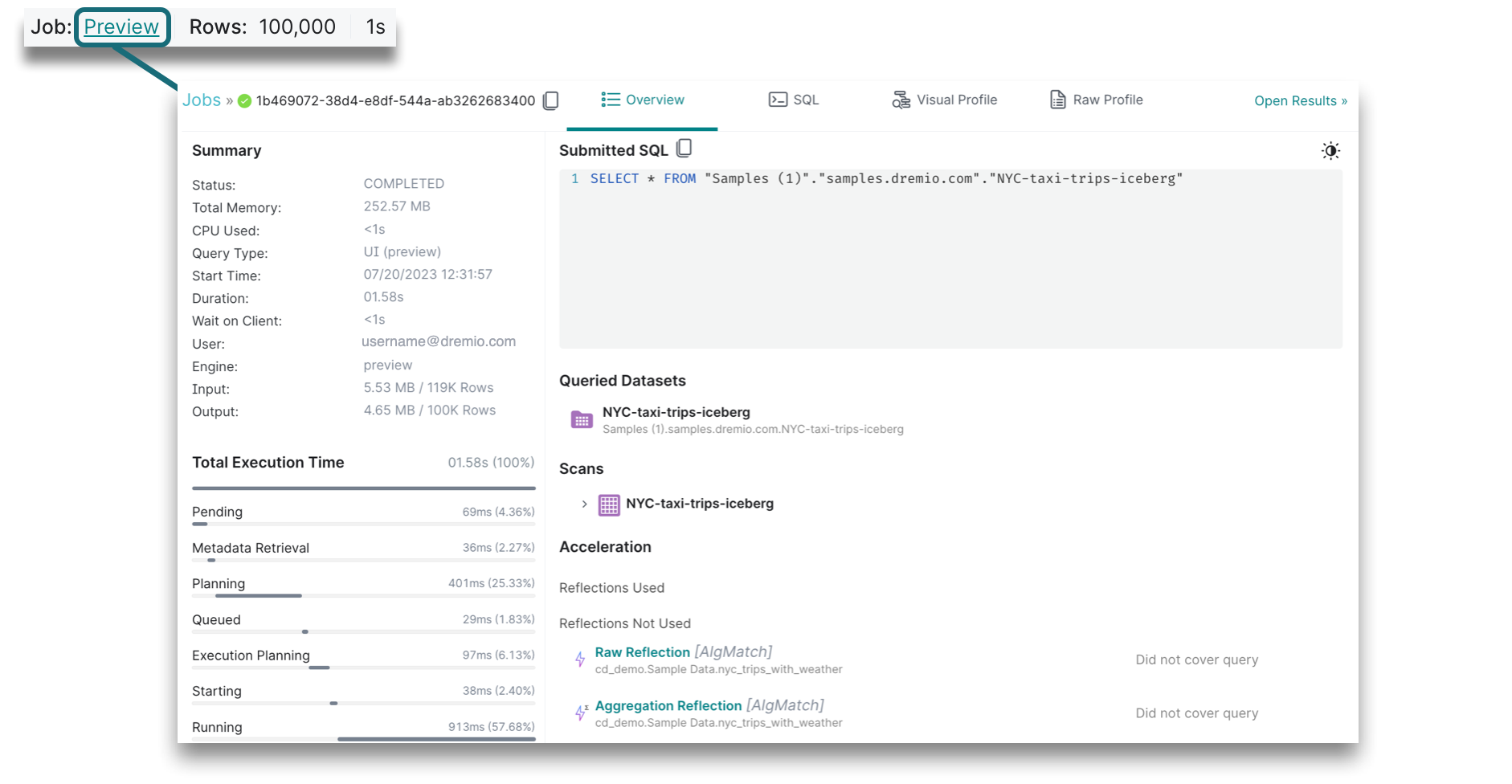
The execution state will show you the type of job that was run, the number of records, and the amount of time that it took to run the query. When you click on the linked job, you will be directed to the Jobs page for a summary, execution time, and more details. If the job took too long or failed, viewing the job details can help you troubleshoot what actually happened.
You can edit a result value directly if you click and drag your cursor over the result value, which opens a dropdown of available edit options such as to replace, keep only, exclude, or copy the result value.
9. Transformations
Transformations can be applied to data. Using the following no-code UI flows automatically updates the SQL in the SQL editor:
Add Column
Group By
Join
Filter Columns
noteIf you are using the preview mode, transformations use a subset of the results and may not provide a complete profile of the result set. It may show null or incomplete values in the dataset as a result of joining, grouping, or calculating fields. You may encounter an error showing "no rows returned due to the LIMIT logic" or "more rows returned due to an outer join".
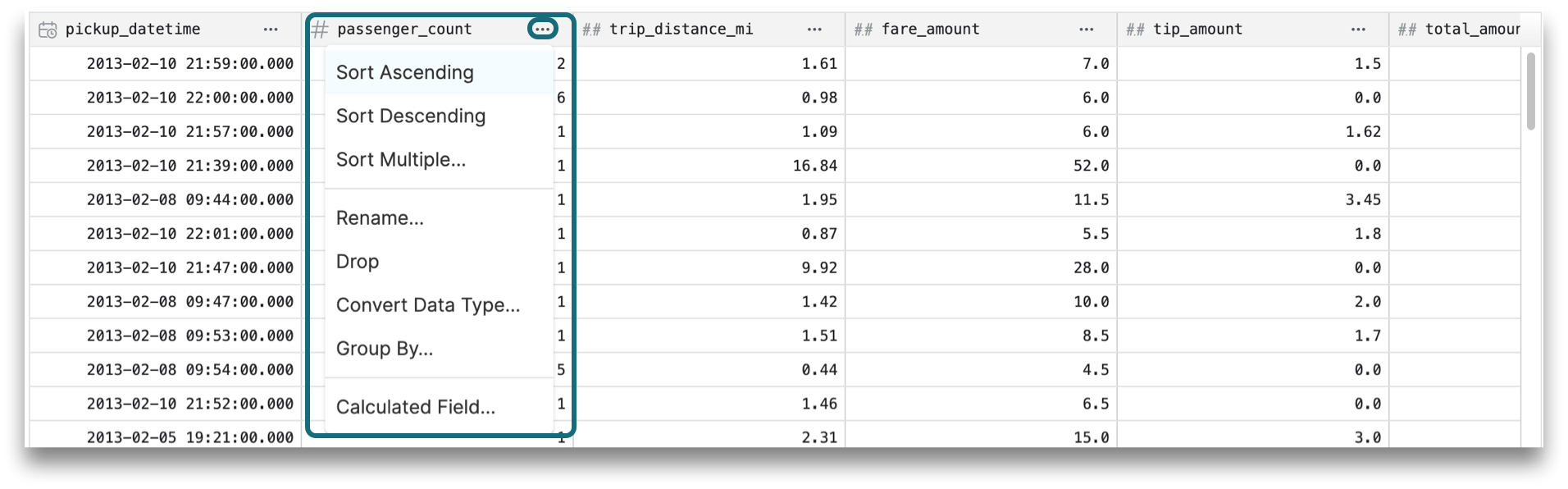
10. Results Table
The results of the query are shown in a table format. You can edit a table column by clicking directly on the column title to open a dropdown of edit options, which include sorting results, converting data types, renaming columns, and calculating fields.
Downloading large result sets could produce delays and errors. If you encounter these issues, create smaller views that summarize the results. You can then run queries on these smaller views and download the results.