Types of Reflections
There are two primary types of Reflections: raw and aggregation. Another type is external.
Raw Reflections
A Reflection of this type consists of all of the rows and one or more fields of the underlying table or view that it is created from. The most basic raw Reflection is equivalent to a SELECT * FROM the corresponding table or view. You can customize raw Reflections by vertically partitioning data (choosing a subset of fields), horizontally partitioning the data (by defining one or more columns to be partition keys), and sorting the data on one or more fields.
A raw Reflection has the same number of records as its anchor, but it is normally a small fraction of the size of the anchor. In many cases, only a small subset of the columns are queried by users, and therefore, it makes sense to include only those columns in the raw Reflection.
Benefits of Using Raw Reflections
Accelerate Queries on Unoptimized Data or Slow Storage
Depending on the source, the underlying table or view may be suboptimal for scan-intensive workloads. In addition, the format of the data may be inefficient for scans (e.g., JSON, CSV), and the source may be accessible only through a slow network connection. If the source data is stored in a non-columnar format, using a raw Reflection can dramatically improve the performance of queries.
Accelerate "Needle-in-a-haystack" Queries
Raw Reflections preserve row-level data in a form that is optimized for scans. You can sort and partition the data on specific fields to allow Dremio’s query optimizer to make use of how the data is physically organized to improve query performance.
Use Fewer Resources on Production Data Sources
If a data source is deployed for operational workloads, there is a good chance it is not optimized for scan-intensive workloads. Raw Reflections allow Dremio to execute most analytical queries without touching the data source.
Transformations applied to data within the query can be expensive to compute, especially for elaborate CASE statements and functions. Rather than use system resources to calculate expensive transformations, queries can use raw Reflections that store the results of transformations. Queries can achieve sub-second response times by using such pre-computed results.
Accelerate Queries on Subsets of Columns in a Table or View
When a table or view includes hundreds of fields, queries against it usually do not include each field. If you create Reflections on subsets of fields, Dremio’s query optimizer uses the fewest of them that satisfies queries against the table or view, requiring scans of far less data.
Accelerate Queries on Subsets of Rows in a Table or View
Predicates that filter the data to subsets can be expensive. In addition, resulting subsets can be significantly smaller than the total table or view, meaning that far more data was scanned than necessary. When you select a field on which to partition a Reflection, Dremio maintains physical partitions of the data. Dremio’s query optimizer prunes partitions when appropriate to optimize query execution.
Accelerate Queries That Perform Complex Joins
Joining data between tables, views, or both can be both CPU and memory intensive, especially when the tables and views involved are larger than memory, or the tables and views reside in different locations. Using a raw Reflection to pre-join data from one or more sources can significantly improve performance.
Accelerate Queries That Sort Large Tables or Views
Sorting large, unsorted tables or views can be memory intensive, especially when the tables or views involved are larger than memory. You can create raw Reflections for which the data is already sorted.
Aggregation Reflections
These Reflections accelerate BI-style queries that involve aggregations (GROUP BY queries) They can also be configured to work on a subset of the fields of a data source.
Aggregation Reflections are summaries of anchors, and therefore should have fewer records. The total number of records in the aggregation Reflection can be calculated as the product of the number of unique values in each of the dimension columns. When the number of unique values in the dimension columns is low, the aggregation will be relatively small, and when there are many unique values it will be larger. For an example, see the section on aggregation Reflections above.
While it is possible to define an aggregation Reflection that has the same number of records as its anchor (by selecting a dimension with the same cardinality as the table or view), this would defeat the purpose of the aggregation Reflection and would be equivalent to using a raw Reflection on that table or view.
Benefits of Using Aggregation Reflections
Use aggregation Reflections to store pre-computed aggregations for combinations of dimensions in tables or views. Doing so improves the efficiency of GROUP BY statements, as well as SQL aggregation functions such as SUM and AVG, in queries issued by your data consumers.
By pre-aggregating data and pre-computing measures (sum, count, min, max, etc), these expensive (cpu, ram) operations can be bypassed entirely at query runtime.
External Reflections
You can accelerate queries by running them against table materializations that are in a connected data source. You select your source data, and then you create a derived table, such as an aggregation. Next, in Dremio Cloud, you define a view that matches the derived table. Finally, you map the view to the derived table. The mapping is an external Reflection.
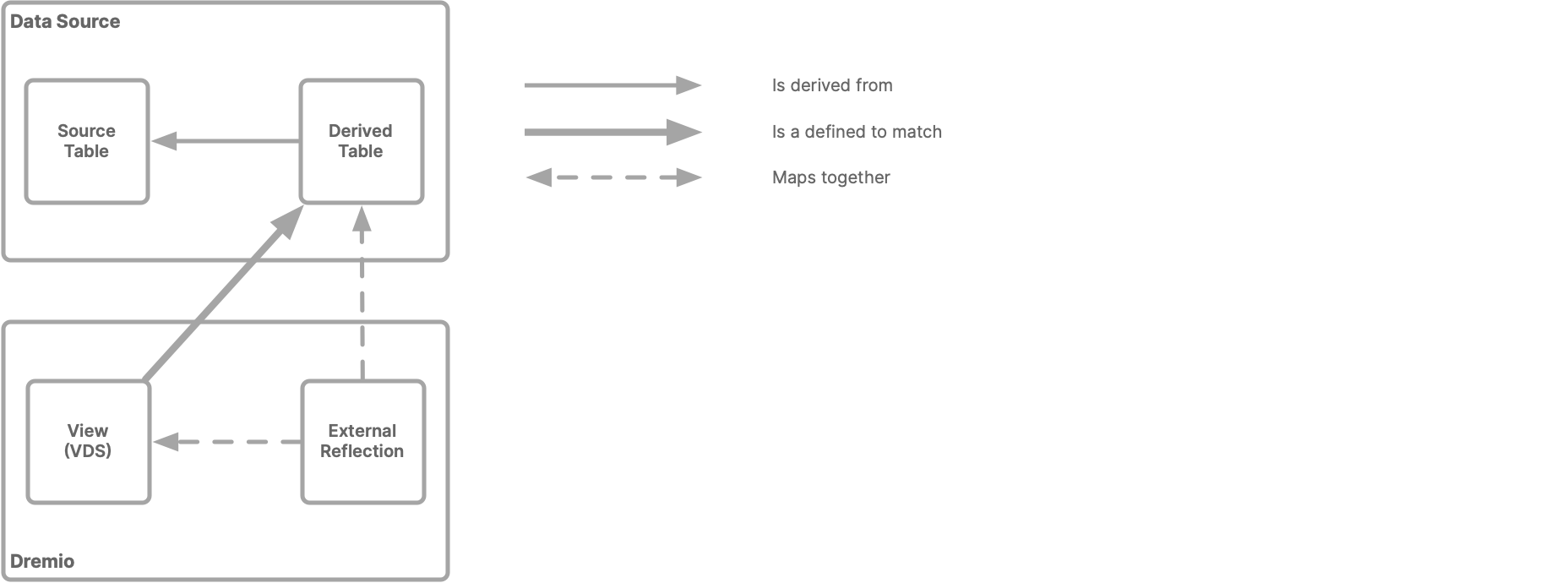
Dremio Cloud users can query the view, and the query planner can consider using the external Reflection when devising the best plans for these queries.
Benefits of External Reflections
- You can use derived tables in your data source directly, without going through the steps of creating a Dremio table from a source table, then a view on the Dremio table, and then a Reflection on the view.
- You do not set a refresh policy or an expiration policy on the data in the derived table.
- You do not use store the data for the derived table in your Dremio cluster.
- You do not need to use the resources of your Dremio cluster to refresh the Reflection periodically.
Starflake Reflections
When materializing Reflections on datasets with joins, Dremio keeps statistics and detects relationships for each join (e.g. 1-1, many-1). If the joins are non-expanding, Dremio can leverage this property to accelerate a larger set of queries. A non-expanding join is a join in which every row in the left table participates at most once in the result. If a user creates a Reflection on a dataset that joins a fact table with three dimension tables, given that this Reflection meets the above criterion, Dremio can accelerate queries that include any subset of these joins (e.g. fact table joined with just one of the dimension tables), without having to define multiple Reflections. Both raw and aggregation Reflections can support starflake acceleration.
Example: Starflake Reflection on Sales
For example, let's assume we have a view (e.g. Enriched Sales Dataset) that joins the following datasets:
- Sales (fact) -
sales_amount,location_id,employee_id,tx_timestamp - Locations(dimension) -
location_id,zip,region_name - Employees (dimension) -
employee_id,position,departmentLet's also assume we have an aggregation Reflection on the aboveEnriched Sales Datasetwith the following configuration: - Dimensions:
zip,region_name,position,department,employee_id,location_id,timestamp - Measures:
sales_amountIn this scenario, if a user is queryingEnriched Sales Dataset, since there is an aggregation Reflection, queries including all combinations of dimensions and measures would be accelerated:
SELECT
AVG(sales_amount) average_sales,
region_name,
position
FROM "Enriched Sales Dataset"
GROUP BY region_name, position
With starflake Reflections, ad-hoc queries that just include any subset of the joins in Enriched Sales Dataset would also be accelerated:
SELECT
SUM(s.sales_amount) average_sales,
l.zip
FROM
Sales s,
Locations l
WHERE s.location_id = l.location_id
GROUP BY l.zip
Queries that were accelerated via starflake Reflections will feature the regular acceleration flame icon, with an added blue starflake icon in the Jobs page.