Managing Workloads
This topic covers how to manage resources and workloads by routing queries to particular engines through rules.
You can use an SQL command to route jobs for refreshing Reflections directly to specified engines. See ROUTE Reflections TO in ALTER TABLE in the SQL reference.
Overview
You can manage Dremio Cloud workloads via routing rules which are evaluated at runtime (before query planning) to decide which engine to use for a given query. In projects with only one engine, all queries share the same execution resources and route to the same single engine. However, when multiple engines are provisioned, rules determine the engine to be used.
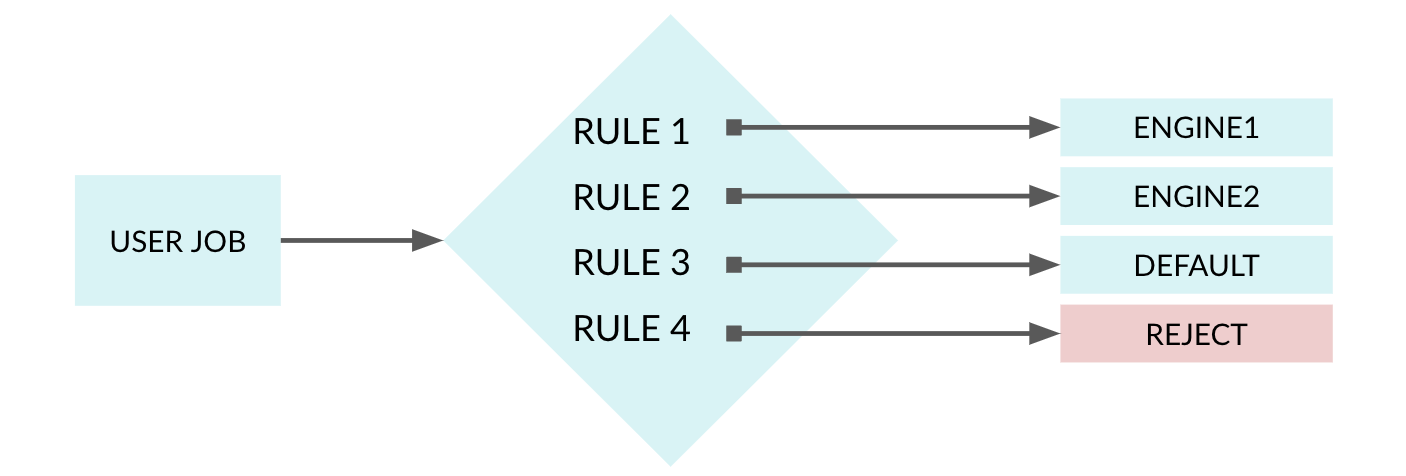
You must arrange the rules in the order that you want them to be evaluated. In the case that multiple rules evaluate to true for a given query, the first rule that returns true will be used to select the engine. The following diagram shows a series of rules that are evaluated when a job gets submitted.
- Rule1 routes jobs to Engine1
- Rule2 routes jobs to Engine2
- Rule3 routes jobs to the default engine that was created on project start up
- Rule4 rejects the jobs that evaluate to true
Rules
You can use Dremio SQL syntax to specify rules to target particular jobs.
The following are the types of rules that can be created along with examples.
User
Create a rule that identifies the user that triggers the job.
Create rule that identifies userUSER in ('JRyan','PDirk','CPhillips')
Group Membership
Create a rule that identifies if the user that triggers the job is part of a particular group.
Create rule that identifies whether user belongs to a specified groupis_member('MarketingOps') OR
is_member('Engineering')
Job Type
Create a rule depending on the type of job. The types of jobs can be identified by the following categories:
- Flight
- JDBC
- Internal Preview
- Internal Run
- Metadata Refresh
- ODBC
- Reflections
- REST
- UI Download
- UI Preview
- UI Run
query_type() IN ('JDBC', 'ODBC', 'UI Run', 'Flight')
Query Label
Labels enable rules that route queries running named commands to specific engines. Dremio supports the following query labels:
| Query Label | Description |
|---|---|
| COPY | Assigned to all queries running a COPY INTO SQL command |
| CTAS | Assigned to all queries running a CREATE TABLE AS SQL command |
| DML | Assigned to all queries running an INSERT, UPDATE, DELETE, MERGE, or TRUNCATE SQL command |
| OPTIMIZATION | Assigned to all queries running an OPTIMIZE SQL command |
Here are two example routing rules:
Create a routing rule for queries running a COPY INTO commandquery_label() IN ('COPY')
query_label() IN ('DML')
Query Attributes
Query attributes enable routing rules that direct queries to specific engines based on their characteristics.
Dremio supports the following query attributes:
| Query Attribute | Description |
|---|---|
DREMIO_MCP | Set when the job is submitted via the Dremio MCP Server. |
AI_AGENT | Set when the job is submitted via the Dremio's AI Agent. |
AI_FUNCTIONS | Set when the job contains AI functions. |
You can use the following functions to define routing rules based on query attributes:
| Function | Applicable Attribute | Description |
|---|---|---|
query_has_attribute(<attr>) | DREMIO_MCP, AI_AGENT, AI_FUNCTIONS | Returns true if the specified attribute is present. |
query_attribute(<attr>) | DREMIO_MCP, AI_AGENT, AI_FUNCTIONS | Returns the value of the attribute (if present), otherwise NULL. |
query_calls_ai_functions() | NA | Returns true if the job has an AI function in the query. |
Examples:
Create a routing rule for queries that use AI functions and are executed by a userquery_calls_ai_functions() AND USER = 'JRyan'
DREMIO_MCP and AI_FUNCTION
query_has_attribute('DREMIO_MCP') AND query_has_attribute('AI_FUNCTIONS')
Tag
Create a rule that routes jobs based on a routing tag.
Create rule that routes jobs based on routing tagtag() = 'ProductionDashboardQueue'
Date and Time
Create a rule that routes a job based on the time it was triggered. Use Dremio SQL Functions.
Create rule that routes jobs based on time triggeredEXTRACT(HOUR FROM CURRENT_TIME)
BETWEEN 9 AND 18
Combined Conditions
Create rules based on multiple conditions.
The following example routes a job depending on user, group membership, query type, query cost, tag, and the time of day that it was triggered.
Create rule based on user, group, job type, query cost, tag, and time triggered(
USER IN ('JRyan', 'PDirk', 'CPhillips')
OR is_member('superadmins')
)
AND query_type() IN ('ODBC')
AND EXTRACT(HOUR FROM CURRENT_TIME)
BETWEEN 9 AND 18
Default Rules
Each Dremio Cloud project has its own set of rules. When a project is created, there are rules that get created for the engines (default and preview) that get created by default. These rules are editable.
| Order | Rule Name | Rule | Engine |
|---|---|---|---|
| 1 | UI Previews | query_type() = 'UI Preview' | preview |
| 2 | Reflections | query_type() = 'Reflections' | default |
| 3 | All Other Queries | All other queries | default |
Viewing All Rules
To view all rules:
- Click the Project Settings
 icon in the side navigation bar.
icon in the side navigation bar. - Select Engine Routing in the project settings sidebar to see the list of engine routing rules.
Adding a Rule
To add a rule:
-
On the Engine Routing page, click the Add Rule button at the top-right corner of the screen.
-
In the New Rule dialog, for Rule Name, enter a name.
-
For Conditions, enter the routing condition. See Rules for supported conditions.
-
For Action, complete one of the following options:
a. If you want to route the jobs that meet the conditions to a particular engine, select the Route to engine option. Then use the engine selector to choose the engine.
b. If you want to reject the jobs that meet the conditions, select the Reject option.
-
Click Add.
Editing a Rule
To edit a rule:
-
On the Engine Routing page, hover over the rule and click the Edit Rule
 icon that appears next to the rule.
icon that appears next to the rule. -
In the Edit Rule dialog, for Rule Name, enter a name.
-
For Conditions, enter the routing condition. See Rules for supported conditions.
-
For Action, complete one of the following options:
a. If you want to route the jobs that meet the conditions to a particular engine, select the Route to engine option. Then use the engine selector to choose the engine.
b. If you want to reject the jobs that meet the conditions, select the Reject option.
-
Click Save.
Deleting a Rule
To delete a rule:
- On the Engine Routing page, hover over the rule and click the Delete Rule
 icon that appears next to the rule.
icon that appears next to the rule.
You must have at least one rule per project to route queries to a particular engine.
- In the Delete Rule dialog, click Delete to confirm.
Per Session Configuration
JDBC and ODBC sessions are held open. This means you can set the session properties once, and they will remain in effect for the lifetime of the session. In contrast, the SQL Runner in the Dremio console does not maintain an open session, so you will need to reset the session properties after you run a query or execute a preview. This behavior applies to all session properties defined in SQL with the SET keyword.
Set and Reset Engines
The SET ENGINE SQL command is used to specify the exact execution engine to run subsequent queries in the current session. When using SET ENGINE, WLM rules and direct routing connection properties are bypassed, and queries are routed directly to the specified queue. The RESET ENGINE command clears the session-level engine override, reverting query routing to follow the Workload Management (WLM) rules or any direct routing connection property if set.
Connection Tagging and Direct Routing Configuration
Routing tags are configured by setting the ROUTING_TAG = <Tag Name> parameter for a given session to the desired tag name.
JDBC Session Configuration
To configure JDBC sessions add the ROUTING_TAG parameter to the JDBC connection URL. For example: jdbc:dremio:direct=localhost;ROUTING_TAG='TagA'.
ODBC Session Configuration
Configure ODBC sessions as follows:
Windows Sessions
Add the ROUTING_TAG parameter to the AdvancedProperties parameter in the ODBC DSN field.
Mac OS Sessions
-
Add the
ROUTING_TAGparameter to theAdvancedPropertiesparameter in the systemodbc.inifile located at/Library/ODBC/odbc.ini. After adding the parameter, an example Advanced Properties configuration might be:AdvancedProperties=CastAnyToVarchar=true;HandshakeTimeout=5;QueryTimeout=180;TimestampTZDisplayTimezone=utc;NumberOfPrefetchBuffers=5;ROUTING_TAG='TagA'; -
Add the
ROUTING_TAGparameter to theAdvancedPropertiesparameter in the user's DSN located at~/Library/ODBC/odbc.ini
Best Practices for Workload Management
Because every query workload is different, engine sizing often depends on several factors, such as the complexity of queries, number of concurrent users, data sources, dataset size, file and table formats, and specific business requirements for latency and cost. Workload management (WLM) ensures reliable query performance by choosing adequately sized engines for each workload type, configuring engines, and implementing query routing rules to segregate and route query workload types to appropriate engines.
This section describes best practices for adding and using Dremio engines, as well as configuring WLM to achieve reliable query performance in Dremio Cloud.
Setting Up Engines
As a fully managed offering, Dremio Cloud is the best deployment model for Dremio in production because it allows you to achieve high levels of reliability and durability for your queries and maximize resource efficiency with engine autoscaling and does not require you to manually create and manage engines.
Segregating workload types into separate engines is vital for mitigating noisy neighbor issues, which can jeopardize performance reliability. You can segregate workloads by type, such as ad hoc, dashboard, and lakehouse (COPY INTO, DML, and optimization), as well as by business unit to facilitate cost distribution.
Metadata and Reflection refresh workloads should have their own engines for executing metadata and Reflection refresh queries. These internal queries can use a substantial amount of engine bandwidth, so assigning separate engines ensures that they do not interfere with user-initiated queries. Initial engine sizes should be XSmall and Small, but these sizes may change depending on the number and complexity of Reflection refresh and metadata jobs.
Dremio recommends the following engine setup configurations:
-
Dremio Cloud offers a range of instance types. Experiment with typical queries, concurrency, and engine sizes to establish the best engine size for each workload type based on your organization's budget constraints and latency requirements.
-
Maximum concurrency is the maximum number of jobs that Dremio can execute concurrently on an engine replica. Dremio provides an out-of-the-box value for maximum concurrency based on engine size, but we recommend testing with typical queries directed to specific engines to determine the best maximum concurrency values for your query workloads.
-
Dremio Cloud offers autoscaling to meet the demands of dynamic workloads with engine replicas. It is vital to assess and configure each engine's autoscaling parameters based on your organization's budget constraints and latency requirements for each workload type. You can choose the minimum and maximum number of replicas for each engine and specify any advanced configuration as needed. For example, dashboard workloads must meet stringent low latency requirements and are prioritized for performance rather than cost. Engines added and assigned to execute the dashboard workloads may therefore be configured to autoscale using replicas. On the other hand, an engine for ad hoc workloads may have budget constraints and therefore be configured to autoscale with a maximum of one replica.
Routing Workloads
Queries are routed to engines according to routing rules. You may use Dremio's out-of-the-box routing rules that route queries to the preview engines that are established by default, but Dremio recommends creating custom routing rules based on your workloads and business requirements. Custom routing rules can combine factors including User, Group Membership, Job Type, Date and Time, Query Label (for lakehouse queries), and ROUTING_TAG (tags; for JDBC and ODBC connections). Read Rules for examples.
The following table lists example routing rules based on query_type, query_label, and tags:
| Order | Rule Name | Rule | Engine |
|---|---|---|---|
| 1 | Reflections | query_type() = 'Reflections' | Reflection |
| 2 | Metadata | query_type() = 'Metadata Refresh' | Metadata |
| 3 | Dashboards | tag() = 'dashboard' | Dashboard |
| 4 | Ad hoc Queries | query_type() IN ( 'UI Run' , 'REST') OR tag() = 'ad hoc' | Ad hoc |
| 5 | Lakehouse Queries | query_label() IN ('COPY','DML','CTAS', 'OPTIMIZATION') | Lakehouse |
| 6 | All Other Queries | All other queries | Preview |
Using the sys.project.history.jobs System Table
The sys.project.history.jobs system table contains metadata for recent jobs executed in a project, including time statistics, cost, and other relevant information. You can use the data in the sys.project.history.jobs system table to evaluate the effectiveness of WLM settings and make adjustments based on job metadata.
Using Job Analyzer
Job Analyzer is a package of useful query and view definitions that you may create over the sys.projects.history.jobs system table and use to analyze job metadata. Job Analyzer is available in a public GitHub repository.