Accelerating Queries
You can accelerate queries with Reflections and the results cache.
Reflections
A Reflection is a precomputed and optimized copy of source data or a query result, designed to speed up query performance. It is derived from an existing table or view, known as its anchor. Reflections can be:
- Autonomous: automatically created and managed by Dremio.
- Manual: created and managed by you.
Dremio's query optimizer can accelerate a query against tables or views by using one or more Reflections to partially or entirely satisfy that query, rather than processing the raw data in the underlying data source. Queries do not need to reference Reflections directly. Instead, Dremio rewrites queries on the fly to use the Reflections that satisfy them.
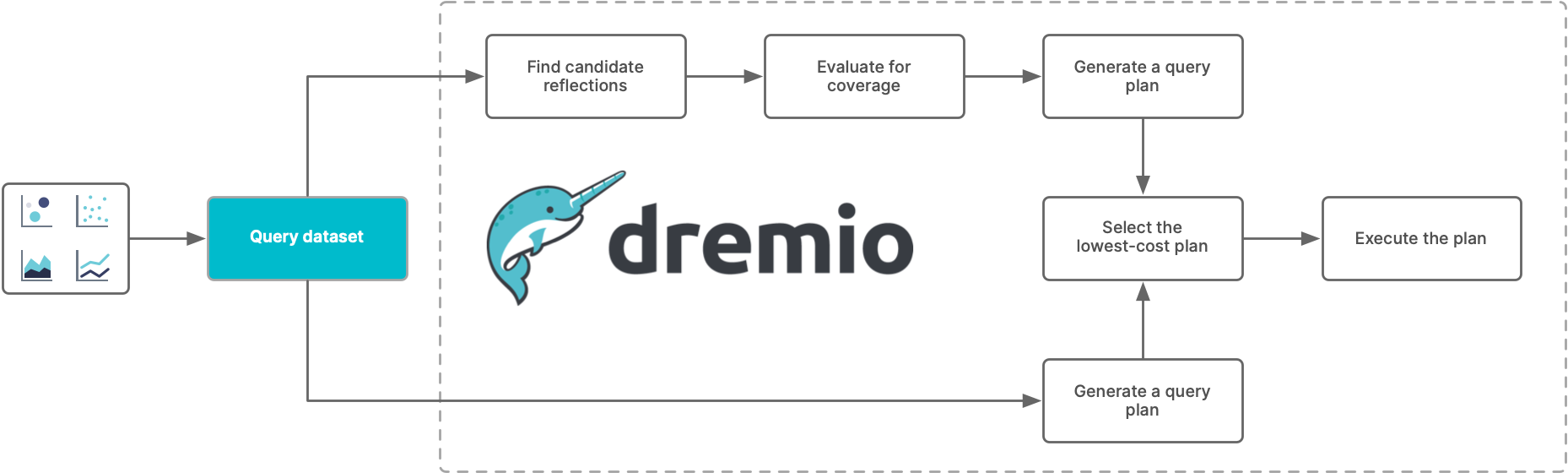
When Dremio receives a query, it determines first whether any Reflections have at least one table in common with the tables and views that the query references. If any Reflections do, Dremio evaluates them to determine whether they satisfy the query. Then, if any Reflections do satisfy the query, Dremio generates a query plan that uses them.
Dremio then compares the cost of the plan to the cost of executing the query directly against the tables, and selects the plan with the lower cost. Finally, Dremio executes the selected query plan. Typically, plans that use one or more Reflections are less expensive than plans that run against raw data. To get the best results from using Reflections, see Best Practices for Creating Raw and Aggregation Reflections.
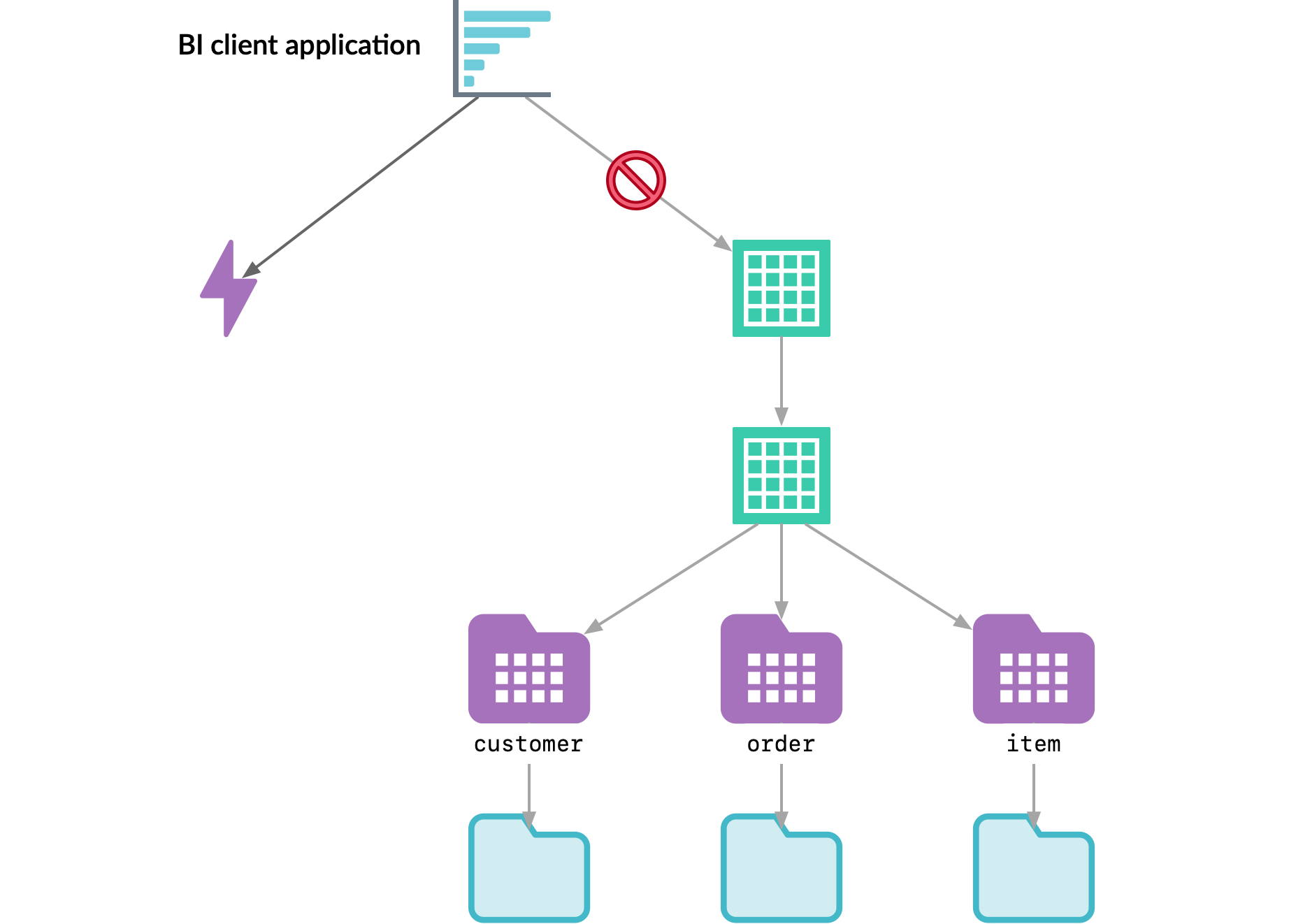
For example, suppose that three tables named customers, orders, and items are created from data sources. A data engineer filling a requirement for allowing single queries across all three tables creates a view named order_detail to join them:
SELECT *
FROM ((order INNER JOIN customer ON order.cust_id = customer.cust_id INNER JOIN item on order.item_id = item.item_id))
A business analyst wants to get a summary of the orders for each customer in the United States. She creates a view named customer_summary_US that is defined by this query on order_detail:
SELECT cust_name, city, COUNT(item_id), SUM(item_price) FROM order_detail
WHERE cust_country = 'US'
GROUP BY cust_name
ORDER BY SUM(item_price) DESC
Because this query is computationally intensive, takes a bit of time to run, and is a query that she runs frequently, the business analyst, together with the data engineer, creates a Reflection from her view, following best practices. They give the Reflection the same name as the view.
The relationships between the Reflection, tables and views, and the data sources can be represented like this:

When the business analyst runs her query from her BI client application, Dremio's query planner runs the query against the Reflection, not against the view customer_summary_US, even though her query references the view. Her query runs much faster because the Dremio engine running it does not have to descend through the tables and views to the raw data in the data source.
As the Dremio Cloud Shared Responsibility Model outlines, Reflections are a shared responsibility between Dremio and you. The Shared Responsibility Model lays out Dremio's responsibilities for defining Reflections and your responsibilities for managing Reflections. For more information, download the PDF guide of the Dremio Cloud Shared Responsibility Model.
Reflections Features and Data Format Compatibility Matrix
The following table outlines the availability of key Reflections features across supported data formats, including enhancements such as Autonomous Reflections, Live Reflections, and Intelligent Incremental Refresh.
| Data Format | Autonomous Reflections | Automatic Raw + Aggregation Recommendation | Manual Reflections | Live Reflections | Automatic Raw Recommendation | Intelligent Incremental Refresh |
|---|---|---|---|---|---|---|
| Iceberg | Yes | Yes | Yes | Yes | Yes | Yes |
| UniForm | Yes | Yes | Yes | Yes | Yes | Yes |
| Parquet | Yes | Yes | Yes | No | Yes | Yes |
| Delta | No | No | Yes | No | No | No |
| Federated Sources | No | No | Yes | No | No | No |
Results Cache
The results cache improves query performance by reusing results from previous executions of the same deterministic query, provided that the underlying dataset remains unchanged and the previous execution was by the same user. The results cache feature works out of the box, requires no configuration, and automatically caches and reuses results. Regardless of whether a query uses the results cache, it always returns the same results.
The results cache is client-agnostic, meaning a query executed in the Dremio console will result in a cache hit even if it is later re-run through other clients like JDBC, ODBC, REST or Arrow Flight. For a query to use the cache, its query plan must remain identical to the original cached version. Any changes to the schema or dataset generate a new query plan, invalidating the cache.
The results cache also supports seamless coordinator scale-out, allowing newly added coordinators to benefit immediately from previously cached results.
Cases Supported By Results Cache
Query results are cached in the following cases:
- The SQL statement is a
SELECTstatement. - The query reads from an Iceberg, Parquet dataset, or from a raw Reflection defined on other Dremio supported data sources and formats, such as relational databases,
CSV,JSON, orTEXT. - The query does not contain dynamic functions such as
QUERY_USER,IS_MEMBER,RAND,CURRENT_DATE, orNOW. - The query does not reference
SYSorINFORMATION_SCHEMAtables, or use external query. - The result set size, when stored in Arrow format, is less than or equal to 20 MB.
- The query is not executed in the Dremio console as a preview.
Viewing Whether Queries Used Results Cache
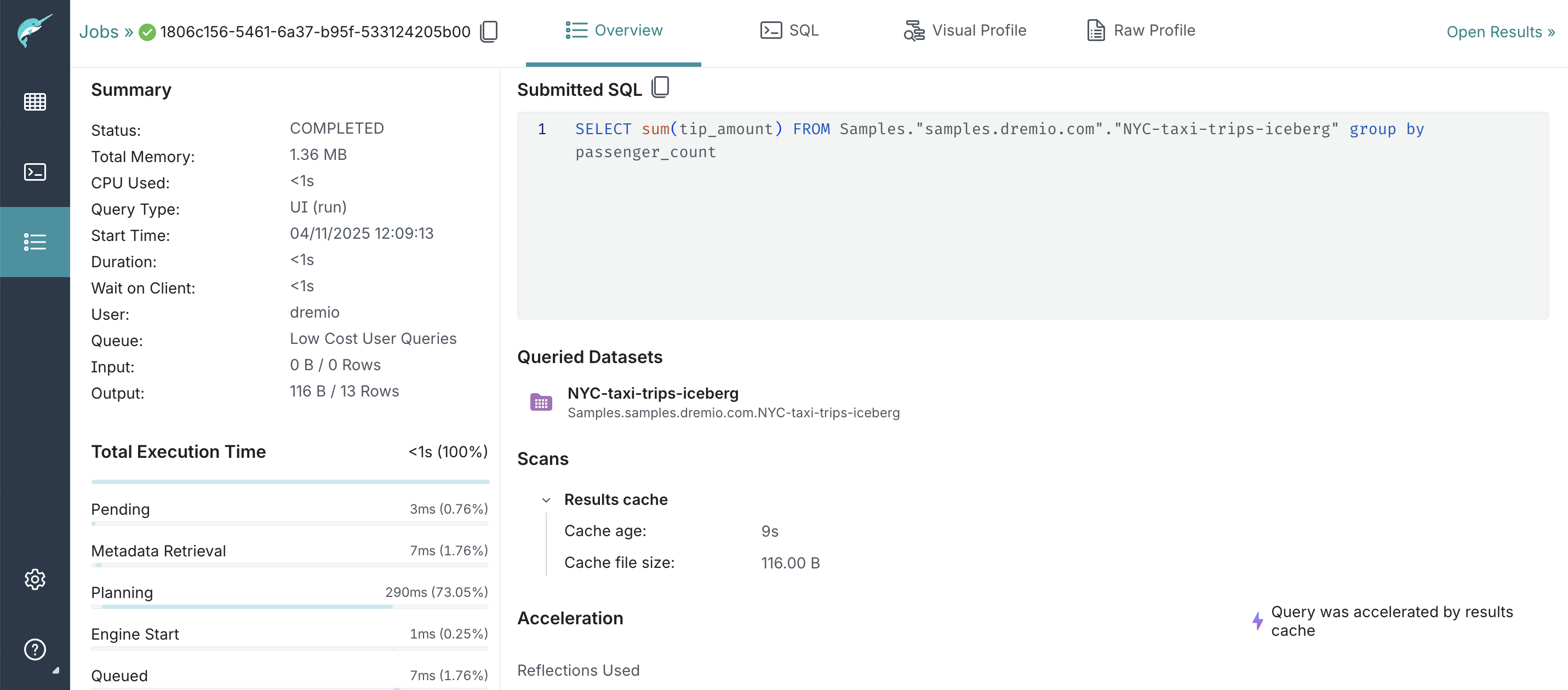
You can view the list of jobs on the Jobs page to determine if queries from data consumers were accelerated by the results cache.
To check whether a query was accelerated by a results cache:
- Find the job that ran the query and look for the lightning-bolt icon next to it. This icon indicates that the query was accelerated using either Reflections or the results cache.
- Click on the row representing the job that ran the query to view the job summary. The summary, displayed in the pane to the right, provides details on whether the query was accelerated using the results cache or Reflections.
Storage
Cached results are stored in the project store alongside all project-specific data, such as metadata and Reflections. Executors write cache entries as Arrow data files and read them when processing SELECT queries that result in a cache hit. Coordinators are responsible for managing the deletion of expired cache files.
Deletion
A background task running on one of the Dremio coordinators handles cache expiration. This task runs every hour to mark cache entries that have not been accessed in the past 24 hours as expired and subsequently deletes them along with their associated cache files.
Considerations and Limitations
SQL queries executed through the Dremio console or a REST client that access the cache will rewrite the cached query results to the job results store to enable pagination.