Dremio Arctic
Dremio Arctic is a lakehouse management service built on Project Nessie and Apache Iceberg. Arctic makes data engineering easy by enabling git-like workflows on data and automating data management operations.
Key features of Arctic include:
- Lakehouse Catalog: Arctic is a native Iceberg catalog for Dremio Cloud. In addition to supporting BI workloads, engines like Dremio Sonar and Spark can load and mutate data directly on tables stored in the Arctic catalog using commands like
INSERT,UPDATE,DELETE, andMERGE. Arctic is implemented as a custom Iceberg catalog, and therefore supports all features available to any Iceberg client. - Data Branching and Versioning: Use Git-like branching to support development, test, and production use cases on the same lakehouse environment, without creating physical copies of data. Experiment and make changes to data without disrupting production workloads, instantly expose changes to users. Easily roll back from mistakes.
- Automatic Optimization: Automate data management tasks like compaction and garbage collection to optimize query performance and minimize storage costs.
- Governance: Secure and track access to data using Role-Based Access Control (RBAC) privileges and a built-in commit log.
- Openness: Use a variety of engines to work with data, including Dremio Sonar, Spark, Flink, and Trino.
Use Cases
- Support development, test, and production on the same environment: Create branches to experiment and make changes to data (such as inserting/updating/deleting data, altering a table's schema, and creating Reflections) without impacting critical workloads running on your main branch. This eliminates the need to create multiple environments and physical copies of data to support various data engineering workloads.
- Instantly promote and audit data changes: Once you've tested and approved changes made in a development branch, you can merge your changes into the main branch for all users to consume instead of physically replicating changes between environments. All changes are tracked with a built-in commit log.
- Recover from mistakes immediately: If a recent change to your data results in problems such as performance degradation or query failure, you can easily roll back changes to a prior state of your lakehouse and immediately recover from mistakes instead of spending hours trying to identify and undo errors.
- Easily experiment with data and reproduce models: Create branches for data scientists to experiment with data, simulate different scenarios, and train models on different versions of data, instead of creating separate physical environments. Use tags to track and refer the state of your environment at a certain point in time, so you can recreate prior results and compare them with the current state of data.
- Eliminate data maintenance: Query performance may be impacted as you ingest and make changes to data. For example, small files produced by data ingestion jobs result in slower queries because the query engine needs to read more files. With Arctic, you can automate data optimization processes to ensure optimal query performance while eliminating the need to spend time on manual data maintenance.
Architecture
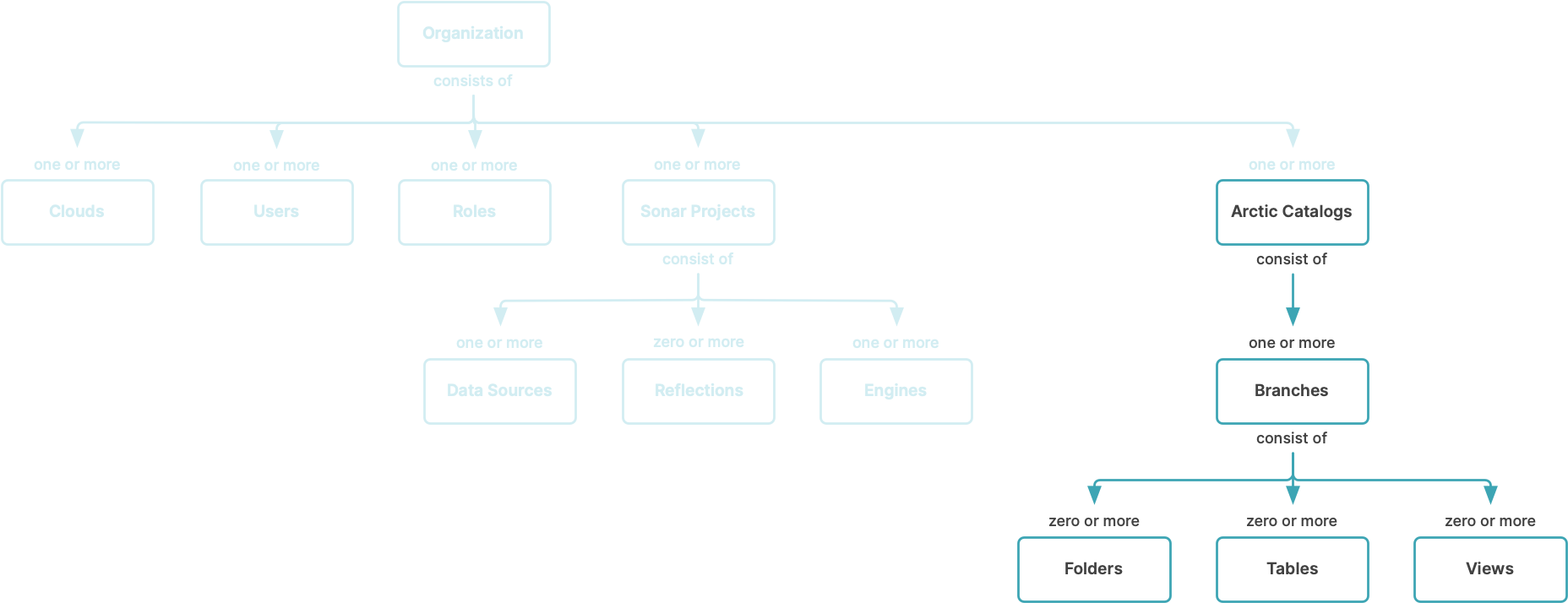
Dremio Arctic is a service within the Dremio Cloud platform. Architecturally, Arctic consists of two key services:
- A Catalog Service, which enables a git-like experience on Iceberg tables and views, with commits, branches, and tags. The catalog service does not store data itself, but only pointers to it. The data is separated from the catalog and stored inside the customer's cloud account.
- An Optimization Service, which automates management tasks for Apache Iceberg tables. The optimization service creates ephemeral Sonar engines inside the customer's cloud account to run optimization tasks on Iceberg tables, so data processing stays in the customer's cloud account. Engines are discarded when optimization tasks are completed.
The following image outlines the high-level architecture of Arctic:
Object Model
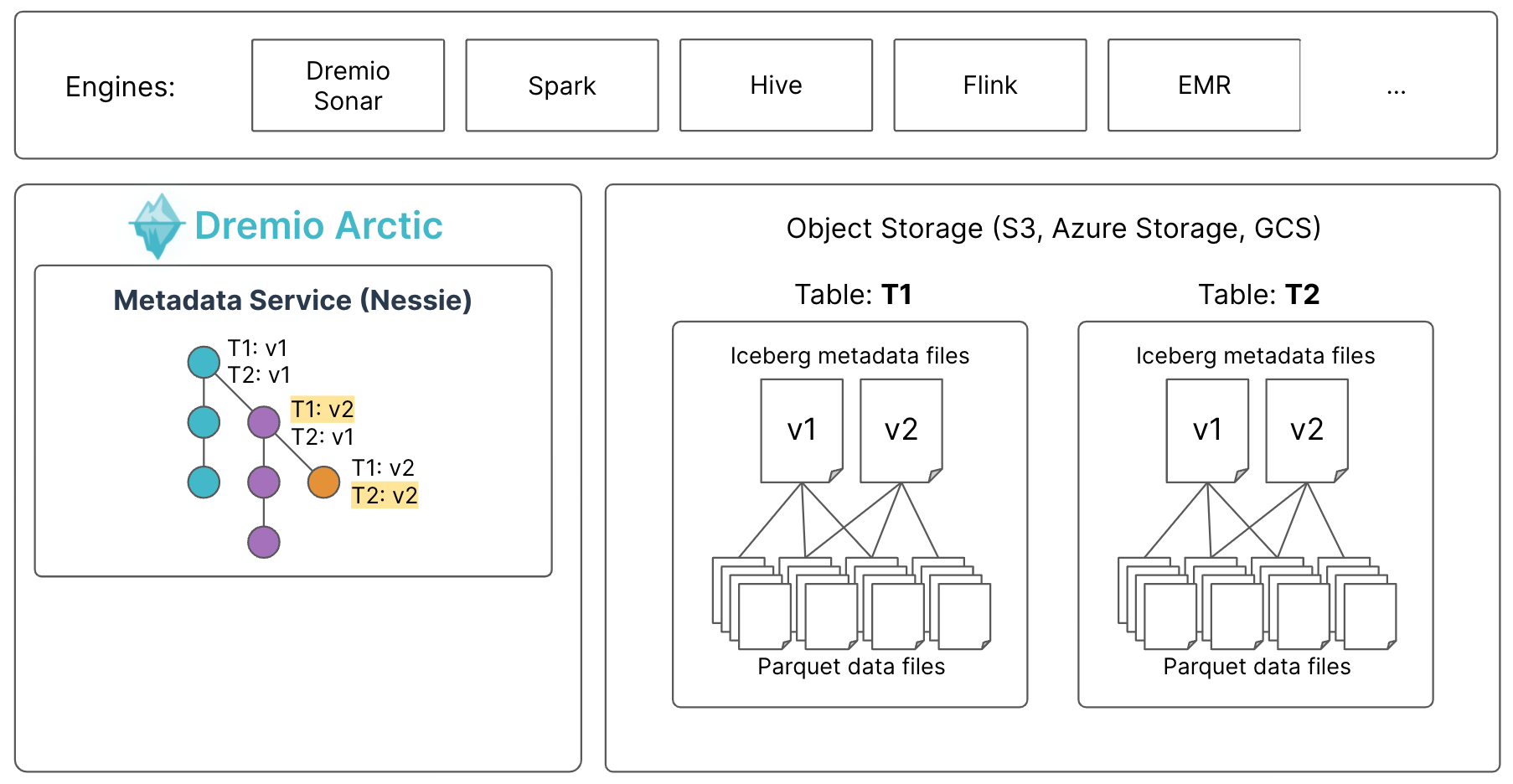
The Arctic object model consists of the following objects:
- Catalog: Catalogs are the top-level object in the Arctic object model.
- Branch: Branches track different versions of data in a catalog. Branches do not contain data, but references to data files that comprise the tables for a specific version of the catalog. More precisely, a branch is a named reference to a series of commits in a catalog. Each Arctic catalog is initialized with a single branch named
main. - Folder: Folders can contain tables, views, and other folders. Folders can be used to organize data in Arctic.
- Table: Tables contain the data from your source, formatted as rows and columns. Tables can be modified by query engines that connect to Arctic. Tables in Arctic use the Apache Iceberg table format.
- View: Views are virtual tables based on the result sets of queries. Views do not contain any data. You can create views from data that resides in any data source, folder, table, or view that you have access to. Views in Arctic leverage the Iceberg view specification.
The following image provides a visual overview of the Arctic object model, in relation to the overall Dremio Cloud object model: