Hive
This topic describes Hive data source considerations and Dremio configuration.
Dremio and Hive
Dremio supports the following:
- Hive 2.1
- Hive 3.x
Data Sources
The following data sources are supported:
-
HDFS
-
MapR-FS
-
Azure Storage
-
S3 - See S3 on Amazon EMR Configuration for more information about S3-backed Hive tables on Amazon EMR.
-
Hive external tables backed by HBase storage handler
Formats
The following formats are supported:
- Apache Iceberg
- Apache Parquet
- Delta Lake
- ORC
- RCFile
- SequenceFile
- Text, including CSV (Comma-separated values)
In addition, the following interfaces and reading file formats are supported:
-
Hive table access using Hive's out-of-the-box SerDes interface, as well as custom SerDes or InputFormat/OutputFormat.
-
Hive-supported reading file format using Hive's own readers -- even if Dremio does not support them natively.
noteDremio does not support Hive views. However, you can create and query views instead.
Hive Configuration
This section provides information about Hive configuration.
Adding additional elements to Hive plugin classpaths
Hive plugins can be extended to use additional resource files and classes. The plugins can be added as either directories or JAR files. Note that any resources that are part of the server's classpath are not exposed to the Hive plugin.
To add additional classpath elements, follow these steps on every node of your Dremio cluster:
-
Create the following directory:
<dremio-root>/plugins/connectors/<hive-plugin-id>.d/
where:-
<dremio-root>is the root directory of the Dremio instance. -
<hive-plugin-id>is either of these values:-
If you are using Dremio Community/OSS and either Hive 2 or Hive 3:
hive3 -
If you are using Dremio Enterprise and either Hive 2 or Hive 3:
hive3-ee
-
-
-
Either place each JAR file in the new directory or add a symlink to each JAR file from the new directory.
-
Either place a copy of each resource directory in the new directory or add a symlink to each resource directory from the new directory.
-
Ensure the directory and its contents are readable by the Dremio process user.
Configuration Files
Hive plugins do not use elements present in the main Dremio server classpath. This includes any Hadoop/Hive configuration files such as core-site.xml and hive-site.xml that the user may have added themselves.
You can add these files to the Hive plugin classpath by following the instructions above.
For example you can create conf files here:
<dremio-root>/plugins/connectors/**hive3-ee.d**/conf for the Hive 3 plugin
in Enterprise mode.
An easy way to use the same configuration as Dremio is to use a symlink. From <dremio-root>:
ln -s conf plugins/connectors/hive3-ee.d/conf
Impersonation
If you are using Ranger-based authorization for your Hive source, refer to Disabling Impersonation for Ranger-Based Authorization.
To grant the Dremio service user the privilege to connect from any host and to impersonate a user belonging to any group, modify the core-site.xml file with the following values:
Grant user impersonation privileges<property>
<name>hadoop.proxyuser.dremio.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.dremio.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.dremio.users</name>
<value>*</value>
</property>
To modify the properties to be more restrictive by passing actual hostnames and group names, modify the core-site.xml file with the following values:
Grant more restrictive user impersonation privileges<property>
<name>hadoop.proxyuser.super.hosts</name>
<value>10.222.0.0/16,10.113.221.221</value>
</property>
<property>
<name>hadoop.proxyuser.dremio.users</name>
<value>user1,user2</value>
</property>
Disabling Impersonation for Ranger-Based Authorization
If you are using Ranger-based authorization, we recommend that you disable impersonation for your Hive source:
- In the Dremio console, open the Source Settings for the Hive source and click Advanced Options.
- Under Connection Properties, add the property
hive.server2.enable.doAsin the Name field and add the settingfalsein the Value field. - Click Save.
Table Statistics
By default, Dremio utilizes its own estimates for Hive table statistics when planning queries.
However, if you want to use Hive's own statistics, do the following:
-
Set the
store.hive.use_stats_in_metastoreparameter to true.
Example:true:store.hive.use_stats_in_metastore -
Run the
ANALYZE TABLE COMPUTE STATISTICScommand for relevant Hive tables in Hive. This step is required so that all of the tables (that Dremio interacts with), have up-to-date statistics.
ANALYZE TABLE <Table1> [PARTITION(col1,...)] COMPUTE STATISTICS;
Hive Metastores
If you are using a Hive source and an HA metastore (multiple Hive metastores),
then you need to specify the following hive.metastore.uris parameter and value in the hive-site.xml file.
<name>hive.metastore.uris</name>
<value>thrift://metastore1:9083,thrift://metastore2:9083</value>
Configuring Hive as a Source
- On the Datasets page, to the right of Sources in the left panel, click
 .
. - In the Add Data Source dialog, under Metastores, select Hive 2.x or Hive 3.x.
General Options
-
Name -- Hive source name. The name cannot include the following special characters:
/,:,[, or]. -
Connection -- Hive connection and security
-
Hive Metastore Host -- IP address. Example: 123.123.123.123
-
Port -- Port number. Default: 9083
-
Enable SASL -- Box to enable SASL. If you enable SASL, specify the Hive Kerberos Principal.
-
-
Authorization -- Authorization type for the client. When adding a new Hive source, you have the following client options for Hive authorization:
-
Storage Based with User Impersonation -- A storage-based authorization in the Metastore Server which is commonly used to add authorization to metastore server API calls. Dremio utilizes user impersonation to implement Storage Based authorization
-
When Allow VDS-based Access Delegation is enabled (default), the owner of the view is used as the impersonated username.
-
When Allow VDS-based Access Delegation is disabled (unchecked), the query user is used as the impersonated username.
-
-
SQL Based -- Not Currently Supported
-
Ranger Based -- An Apache Ranger plug-in that provides a security framework for authorization.
-
Ranger Service Name - This field corresponds to the security profile in Ranger. Example:
hivedev -
Ranger Host URL - This field is the path to the actual Ranger server. Example:
http://yourhostname.com:6080
-
-
Advanced Options
The following options allow you to specify either impersonsation users and Hive connection properties.
For example, to add a new Hive source, you can specify a single metastore host
by adding a hive.metastore.uris parameter and value in the Hive connection properties.
This connection property overrides the value specified in the Hive source.
Multiple Hive Metastore Hosts: If you need to specify multiple Hive metastore hosts, update the hive-site.xml file. See Hive Metastores for more information.
-
Impersonation User Delegation -- Specifies whether an impersonation username is As is (Default), Lowercase, or Uppercase
-
Connection Properties -- Name and value of each Hive connection property.
-
Credentials -- Name and hidden value of each Hive connection property for which you want to keep the value secret.
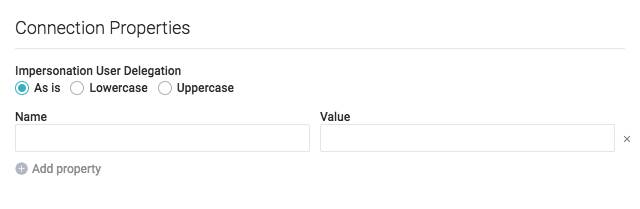
Kerberized Hive
To connect to a Kerberized Hive source, add the following connection property in the Advanced Options:
| Property | Description | Value |
|---|---|---|
| yarn.resourcemanager.principal | Name of the Kerberos principal for the YARN resource manager. | <user>/<localhost>@<YOUR-REALM.COM> |
Reflection Refresh
-
Never refresh -- Specifies how often to refresh based on hours, days, weeks, or never.
-
Never expire -- Specifies how often to expire based on hours, days, weeks, or never.
Metadata
Dataset Handling
- Remove dataset definitions if underlying data is unavailable (Default).
If this box is not checked and the underlying files under a folder are removed or the folder/source is not accessible, Dremio does not remove the dataset definitions. This option is useful in cases when files are temporarily deleted and put back in place with new sets of files.
Metadata Refresh
-
Dataset Discovery -- Refresh interval for top-level source object names such as names of DBs and tables.
- Fetch every -- Specify fetch time based on minutes, hours, days, or weeks. Default: 1 hour
-
Dataset Details -- The metadata that Dremio needs for query planning such as information needed for fields, types, shards, statistics, and locality.
-
Fetch mode -- Specify either Only Queried Datasets, or All Datasets. Default: Only Queried Datasets
-
Only Queried Datasets -- Dremio updates details for previously queried objects in a source.
This mode increases query performance because less work is needed at query time for these datasets. -
All Datasets -- Dremio updates details for all datasets in a source. This mode increases query performance because less work is needed at query time.
-
-
Fetch every -- Specify fetch time based on minutes, hours, days, or weeks. Default: 1 hour
-
Expire after -- Specify expiration time based on minutes, hours, days, or weeks. Default: 3 hours
-
-
Authorization -- Used when impersonation is enabled. Specifies the maximum of time that Dremio caches authorization information before expiring.
- Expire after - Specifies the expiration time based on minutes, hours, days, or weeks. Default: 1 day
Privileges
On the Privileges tab, you can grant privileges to specific users or roles. See Access Controls for additional information about privileges.
All privileges are optional.
- For Privileges, enter the user name or role name that you want to grant access to and click the Add to Privileges button. The added user or role is displayed in the USERS/ROLES table.
- For the users or roles in the USERS/ROLES table, toggle the checkmark for each privilege you want to grant on the Dremio source that is being created.
- Click Save after setting the configuration.
Updating a Hive Source
To update a Hive source:
- On the Datasets page, under Metastores in the panel on the left, find the name of the source you want to edit.
- Right-click the source name and select Settings from the list of actions. Alternatively, click the source name and then the
 at the top right corner of the page.
at the top right corner of the page. - In the Source Settings dialog, edit the settings you wish to update. Dremio does not support updating the source name. For information about the settings options, see Configuring Hive as a Source.
- Click Save.
Deleting a Hive Source
If the source is in a bad state (for example, Dremio cannot authenticate to the source or the source is otherwise unavailable), only users who belong to the ADMIN role can delete the source.
To delete a Hive source, perform these steps:
- On the Datasets page, click Sources > Metastores in the panel on the left.
- In the list of data sources, hover over the name of the source you want to remove and right-click.
- From the list of actions, click Delete.
- In the Delete Source dialog, click Delete to confirm that you want to remove the source.
Deleting a source causes all downstream views that depend on objects in the source to break.
For More Information
See Hive Data Types for information about mapping to Dremio data types.