Apache Iceberg
Apache Iceberg is an open table format designed for gigantic, petabyte-scale tables and is rapidly becoming an industry standard for managing data in data lakes. A table format helps you manage, organize, and track all of the files that make up a table. Iceberg was created to solve challenges with traditional file formatted tables in data lakes including data and schema evolution and consistent concurrent writes in parallel. Additionally, Iceberg introduces new capabilities that enable multiple applications, such as Dremio, to work together on the same data in a transactionally consistent manner and defines additional information on the state of datasets as they evolve and change over time.
Dremio integrated support for Iceberg tables to leverage powerful SQL database-like functionality through industry standard methods for data lakes. Additionally, Dremio supports the time travel and metadata capabilities available in Iceberg tables.
Apache Iceberg is supported in v21.0+.
For the syntax of the SQL commands that Dremio supports for Iceberg tables, see SQL Commands for Apache Iceberg Tables.
For a deeper dive into Apache Iceberg, see:
How Dremio Uses Iceberg Tables
The Iceberg table format has similar capabilities and functionality to SQL tables in traditional databases. Unlike such datasets, Iceberg functions in a fully-open and accessible manner that allows multiple engines (such as Dremio, Spark, etc.) to operate on the same dataset.
Via metadata files (that is, manifests), Iceberg tracks point-in-time snapshots by maintaining all deltas as a table. Each snapshot provides a complete description of the table’s schema, partition, and file information. Additionally, Iceberg intelligently organizes snapshot metadata in a hierarchical structure. This enables Dremio to employ fast and efficient changes to tables without redefining all dataset files, thus ensuring optimal performance when working at data lake scale.
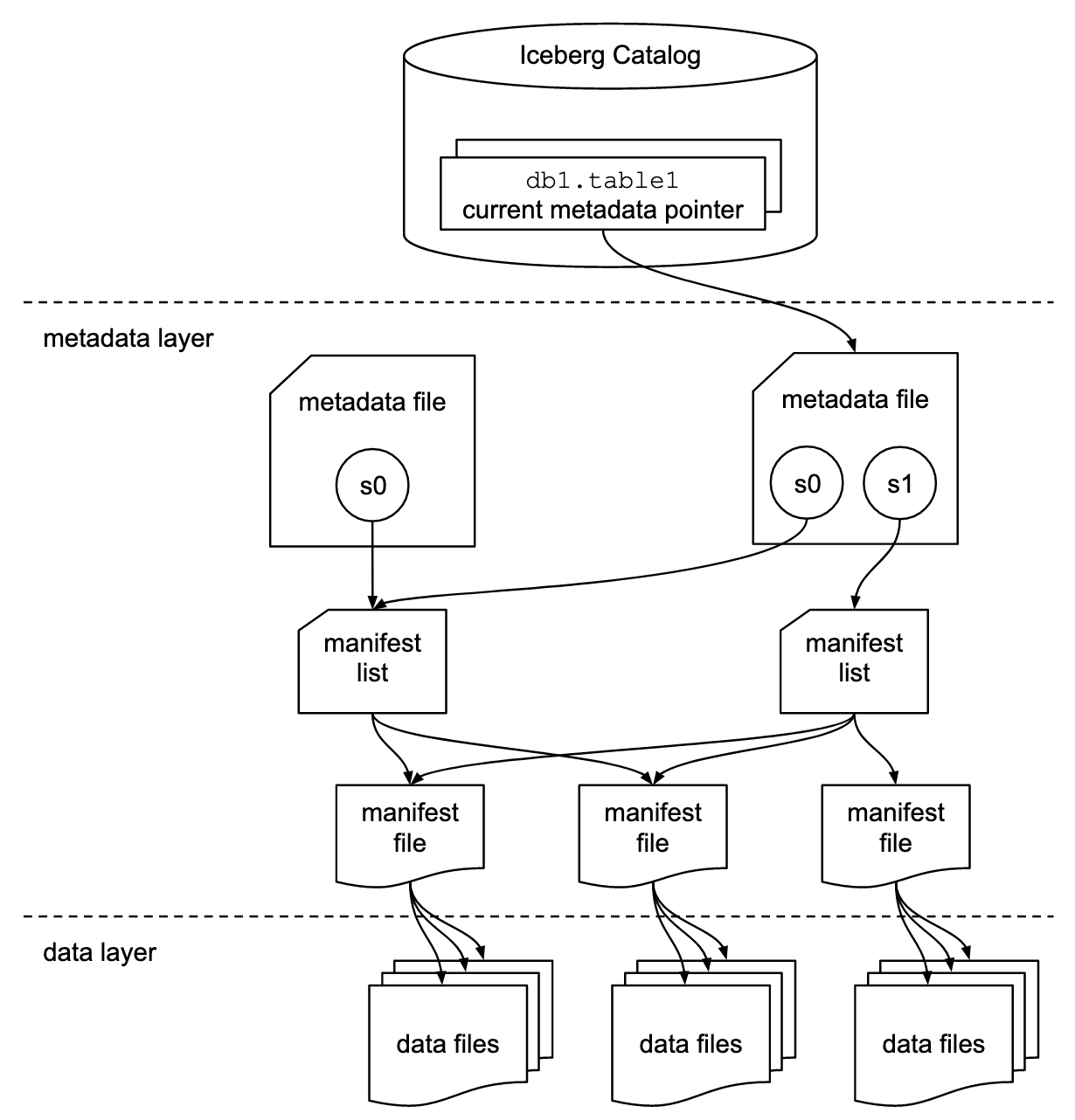
The Iceberg table's architecture consist of three layers:
- The Iceberg catalog: The catalog is where services go to find the location of the current metadata pointer, which helps identify where to read or write data for a given table. Here is where references or pointers exist for each table that identify each table’s current metadata file.
- The metadata layer: This layer consists of three components: metadata file, manifest list, and manifest file. The metadata file includes information about a table’s schema, partition information, snapshots, and the current snapshot. The manifest list contains a list of manifest files, along with information about the manifest files that make up a snapshot. Manifest files track data files in addition to other details and statistics about each file.
- The data layer: Each manifest file tracks a subset of data files, which contain details about partition membership, record count, and lower- and upper-bounds of columns.
Benefits of Iceberg Tables
Iceberg tables offer the following benefits over other formats traditionally used in the data lake, including:
- Schema evolution: Supports add, drop, update, or rename column commands with no side effects or inconsistency.
- Partition evolution: Facilitates the modification of partition layouts in a table, such as data volume or query pattern changes without needing to rewrite the entire table.
- Time travel: Allows users to query any previous versions of the table to examine and compare data or reproduce results using previous queries.
- Increased performance: Ensures data files are intelligently filtered for accelerated processing via advanced partition pruning and column-level statistics.
- Transactional consistency: Helps users avoid partial or uncommitted changes by tracking atomic transactions with atomicity, consistency, isolation, and durability (ACID) properties.
- Version rollback: Corrects any discovered problems quickly by resetting tables to a known good state.
- Table optimization: Optimize query performance to maximize the speed and efficiency with which data is retrieved.
Promoting the Iceberg Table
During table promotion, Dremio automatically identifies newly-created tables using the Apache Iceberg format and refers to the most recent Iceberg snapshot to define the table’s schema, including column names, column types, and partitions.
Iceberg Catalogs in Dremio
The Apache Iceberg table format uses an Iceberg catalog service to track snapshots and ensure transactional consistency between tools. For more information about how Iceberg catalogs and tables work together, see Iceberg Catalog.
Dremio comes with a built-in Iceberg catalog, based on Apache Polaris (incubating). The catalog enables centralized, secure read and write access to your Iceberg tables across various REST-compatible query engines, and automates data maintenance operations to maximize query performance.
Once you create a table using an Iceberg catalog, you cannot access that table from a different Iceberg catalog. Essentially, the catalog is the source of truth for the current metadata pointer for the table. For example, if you create a table using the AWS Glue catalog with Amazon S3 as a backing store for the metadata or data files, then you cannot use a Hadoop catalog pointing to that S3 location to read/write to the table. You would always need to use the Glue catalog to access the table.
Sources that you connect in Dremio use the following catalogs by default, which can support both read and write commands into the Iceberg tables:
| Dremio Source Type | Default Iceberg Catalog |
|---|---|
| AWS Glue | AWS Glue Iceberg catalog |
| Amazon S3 / Azure Storage / GCS / HDFS | Hadoop Iceberg catalog |
| Open Catalog | Apache Iceberg catalog (Iceberg REST) |
| Hive | Hive Iceberg catalog |
| Nessie | Apache Iceberg Catalog |
Iceberg Partitioning in Dremio
The Apache Iceberg table format uses partitioning as a way to make queries faster by grouping similar rows together when writing. Iceberg can partition timestamps by year, month, day, and hour granularity. For more information about how Iceberg handles partitioning, see Partitioning in the Apache Iceberg docs.
Dremio Enterprise supports Iceberg partitioning, including:
- Partition transforms (for example, DAY(event_ts))
- Partition evolution: Iceberg keeps the metadata for each partition version separately. For specific partition evolution that Dremio supports, see Alter Table.
For specific partition transforms that Dremio supports, see Create Table.
Supported Iceberg Metadata Functions
Iceberg includes helpful system table references which provides an easy method for users to access Iceberg specific information on a table, including:
- A table’s history
- The snapshots for a table
- The data files for a table
- The manifest files for a table
For information about querying metadata in Iceberg tables, see Querying Apache Iceberg Tables > Metadata Queries.
Seamless Metadata Refresh
Dremio refreshes Iceberg table metadata during query planning to ensure that you're always querying the latest snapshots of your Iceberg tables with minimal query planning overhead, no matter which data source contains the tables.
During query planning, Dremio requests the catalog to check for a newer version of the Iceberg table than the version that is stored in the query planner cache. If there is no new version, Dremio uses the existing metadata. If there is a new version, Dremio requests the metadata for the new version from the catalog.
To reduce the latency associated with inline metadata refreshes, Dremio's internal catalog management parallelizes some of the metadata operations. This helps reduce latency for complex queries over many underlying views and tables.
For queries that cannot afford the potential for extra latency associated with the inline metadata refreshes, the query hint prefer_cached_metadata instructs the query planner to use the existing table metadata stored in its low-latency cache instead of making catalog requests. In this case, the query might use an out-of-date version of the table, and Dremio will refresh the metadata during the next query on the table that doesn't use the query hint, scheduled metadata refresh on the source, or manual metadata refresh on the table.
Limitations
The following are limitations with Apache Iceberg as implemented in Dremio:
- Only Parquet file formats are currently supported. Other formats (such as ORC and Avro) are not supported at this time.
- Amazon DynamoDB and JDBC catalogs are currently not supported.
- Unable to use DynamoDB as a lock manager with the Hadoop catalog on Amazon S3.
- Dremio does not support reading global equality deletes for Apache Iceberg v2 tables in which the partition spec for the delete file is unpartitioned.