Accelerate Queries
In Dremio, queries can be accelerated with Reflections and results cache.
Reflections
A Reflection is a precomputed and optimized copy of source data or a query result, designed to speed up query performance. It is derived from an existing table or view, known as its anchor. Reflections can be:
- Autonomous: automatically created and managed by Dremio.
- Manual: created and managed by you.
Dremio's query optimizer uses Reflections to accelerate queries by avoiding the need to scan the original data. Instead of querying the raw source, Dremio automatically rewrites queries to use Reflections when they provide the necessary results, without requiring you to reference them directly.
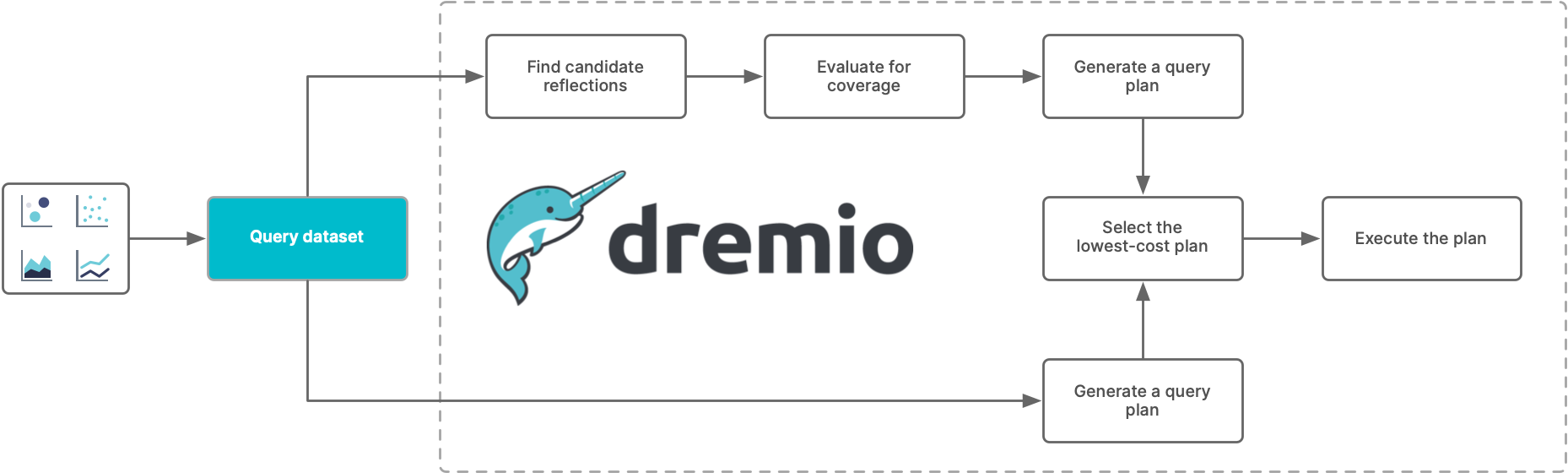
When Dremio receives a query, it determines first whether any Reflections have at least one table in common with the tables and views that the query references. If any Reflections do, Dremio evaluates them to determine whether they satisfy the query. Then, if any Reflections do satisfy the query, Dremio generates a query plan that uses them.
Dremio then compares the cost of the plan to the cost of executing the query directly against the tables, and selects the plan with the lower cost. Finally, Dremio executes the selected query plan. Typically, plans that use one or more Reflections are less expensive than plans that run against raw data.
Types
There are different types of Reflections tailored to specific workloads:
-
Raw Reflections: retain the same number of records as its anchor while allowing a subset of columns. It enhances query performance by materializing complex views, transforming data from non-performant sources into the Iceberg table format optimized for large-scale analytics, and utilizing partitioning and sorting for faster access. By precomputing and storing data in an optimized format, raw Reflections significantly reduce query latency and improve overall efficiency.
-
Aggregation Reflections: accelerate BI-style queries that involve aggregations (GROUP BY queries) by precomputing results (like
SUM,COUNT,AVG,GROUP BY) across selected dimensions and measures. By precomputing expensive computations, they significantly improve query performance at runtime. These Reflections are ideal for analytical workloads with frequent aggregations on large datasets. -
External Reflections: reference precomputed tables in external data sources instead of materializing Reflections within Dremio, eliminating refresh overhead and storage costs. You can use an external Reflection by defining a view in Dremio that matches the precomputed table and map the view to the external data source. The data in the precomputed table is not refreshed by Dremio. When querying the view, Dremio’s query planner leverages the external Reflection to generate optimal execution plans, improving query performance without additional storage consumption in Dremio.
-
Starflake Reflections: optimize multi-table joins by leveraging precomputed relationships between fact and dimension tables. When joins do not duplicate rows, Dremio can accelerate queries using Reflections even if they include only a subset of the joins in Reflections, reducing the need for multiple Reflections on different combinations of tables.
Reflections Features and Data Format Compatibility Matrix
The following table outlines the availability of key Reflections features across supported data formats, including version-specific enhancements such as Autonomous Reflections, Live Reflections, and Intelligent Incremental Refresh.
| Data Format | Autonomous Reflections | Automatic Raw + Aggregation Recommendation | Manual Reflections | Live Reflections (25.1+) | Automatic Raw Recommendation (25.0+) | Intelligent Incremental Refresh (24.3+) |
|---|---|---|---|---|---|---|
| Iceberg | Yes | Yes | Yes | Yes | Yes | Yes |
| UniForm | Yes | Yes | Yes | Yes | Yes | Yes |
| Parquet | Yes | Yes | Yes | No | Yes | Yes |
| Delta | No | No | Yes | No | No | No |
| Federated Sources | No | No | Yes | No | No | No |
Results Cache
Results cache improves query performance by reusing results from previous executions of the same deterministic query, provided that the underlying dataset remains unchanged and the previous execution was by the same user. The results cache feature works out of the box, requires no configuration, and automatically caches and reuses results. Regardless of whether a query uses results cache, it always returns the same results.
Results cache is client-agnostic, meaning a query executed in the Dremio console will result in a cache hit even if it is later re-run through other clients like JDBC, ODBC, REST or Arrow Flight. For a query to use the cache, its query plan must remain identical to the original cached version. Any changes to the schema or dataset generate a new query plan, invalidating the cache.
Cases Supported By Results Cache
Query result are cached in the following cases:
- The SQL statement is a
SELECTstatement. - The query reads from an Iceberg, Parquet dataset, or from a raw Reflection defined on other Dremio supported data sources and formats, such as relational databases,
CSV,JSON, orTEXT. - The query does not contain dynamic functions such as
QUERY_USER,IS_MEMBER,RAND,CURRENT_DATE, orNOW. - The query does not reference
SYSorINFORMATION_SCHEMAtables, or use external query. - The result set size, when stored in Arrow format, is less than or equal to 20 MB.
- The query is not executed in Dremio console as a preview.
Viewing Whether Queries Used Results Cache
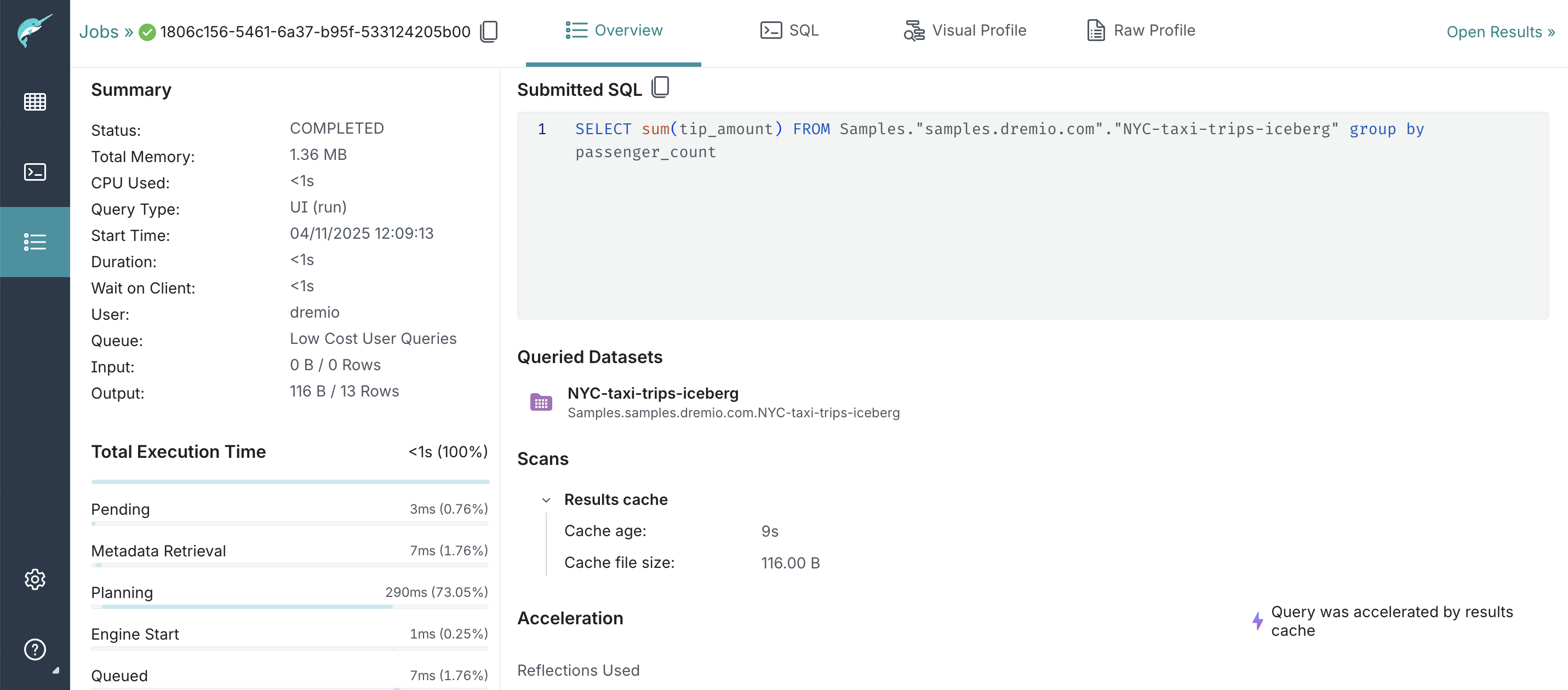
You can view the list of jobs on the Jobs page to determine if queries from data consumers were accelerated by the results cache.
To find whether a query was accelerated by a results cache:
- Find the job that ran the query and look for the lightning-bolt icon next to it. This icon indicates that the query was accelerated using either Reflections or the results cache.
- Click on the row representing the job that ran the query to view the job summary. The summary, displayed in the pane to the right, provides details on whether the query was accelerated using results cache or Reflections.
Storage
Cached results are stored in the distributed storage, configured in dremio.conf. Executors write cache entries as Arrow data files and read them when processing SELECT queries that result in a cache hit. Coordinators are responsible for managing the deletion of expired cache files.
Deletion
A background task running on one of the Dremio coordinators handles cache expiration. This task runs every hour to mark cache entries that have not been accessed in the past 24 hours as expired and subsequently deletes them along with their associated cache files.
Considerations and Limitations
SQL queries executed through the Dremio console or a REST client that access the cache will rewrite the cached query results to the job results store to enable pagination. This behavior will be enhanced in future releases.
Additional Resources
Find out more about Reflections by enrolling in the Data Product Fundamentals course in Dremio University.