Copying Data Into Apache Iceberg Tables
You can load data from CSV, JSON, and Parquet files into existing Iceberg tables. The copy operation loads data into columns in the target table that match corresponding columns represented in the data.
Performing analytics at scale on data that is in CSV or JSON files is not ideal. You can get much faster response times for your queries by querying data in Apache Iceberg tables, which use the column-oriented Parquet file format. This format is column-oriented, and supports efficient data storage and data retrieval at very high volumes and concurrencies. Even the performance of queries on Parquet files can be significantly improved upon by loading their data into Iceberg tables. When your data is in Iceberg tables, you can then make use of all of the features in Dremio's support of such tables.
The copy operation is supported on Iceberg tables in the following types of catalogs:
- AWS Glue Data Catalog
- Hive Metastore
- Nessie Catalog
The storage location can be in the following types of object storage:
- Azure Storage
- Google Cloud Storage
- HDFS
- NAS
- Amazon S3
The copy operation verifies that at least one column in the target table matches a column represented in the data files. It then follows these rules:
- If a match is found, the values in the data files are loaded into the column or columns.
- If additional non-matching columns are present in the data files, the values in these columns are not loaded.
- If additional non-matching columns are present in the target table, the operation inserts
NULLvalues into these columns. - If no column in the target table matches any column represented in the data files, the operation fails.
The copy operation ignores case when comparing column names.
To perform this operation, use the COPY INTO <table> SQL command.
When a copy operation adds new Parquet files to an existing Iceberg table, the operation compresses those files using the codec defined by the write.parquet.compression-codec table property. If you have not configured this property, the operation uses the default Zstandard (zstd) codec to compress the files. For details, see Supported Properties of Apache Iceberg Tables.
Routing to Specific Queues
You can route jobs that run the COPY INTO <table> command to specific queues by using a routing rule that uses the query_label() condition. For more information, see Workload Management.
Requirements
- At least one column in the target table must match a column represented in every data file.
- Do not duplicate column names in files. The operation throws an error if it finds duplicate names.
- CSV data files must have a header line at the start of the file.
Type Coercion
For a list of the type coercions used by the copy operation when copying data from CSV and JSON files, see Type Coercion When Copying Data from CSV or JSON Files Into Apache Iceberg Tables.
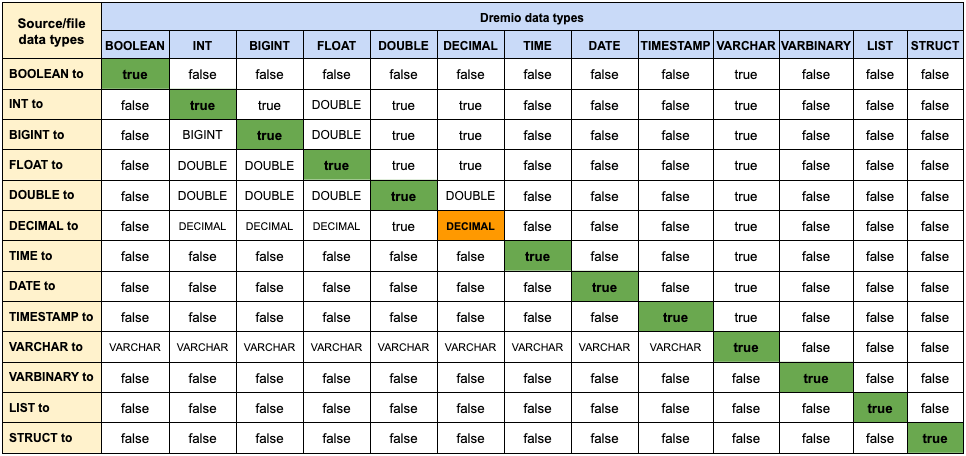
For the type coercions used by the copy operation when copying data from Parquet files, refer to this table:
Column Nullability Constraints
A column's nullability constraint defines whether the column can contain NULL values, because you can specify that each column is either:
NULL— AllowsNULLvalues, which is useful for optional or unknown data.NOT NULL— Requires a value for every row;NULLvalues are not allowed.
When running COPY INTO with ON_ERROR set to 'continue' or 'skip_file', the command will not fail on nullability conflicts. Instead, it skips the problematic file or record.
However, if ON_ERROR is set to 'abort' (or left unspecified), the command will fail if any row violates the table’s NOT NULL constraints.