Viewing a Visual Profile
You can view the operations in visual profiles to diagnose performance or cost issues and to see the results of changes that you make, either to queries themselves or their environment, to improve performance or reduce costs.
Visual Profiles
A query profile details the plan that Dremio devised for running a query and shows statistics from the query's execution. A visual representation of a query profile is located on the Visual Profile tab. This visual profile consists of operators that are arranged as a tree, where each operator has one or two upstream operators that represent a specific action, such as a table scan, join, or sort. At the top of the tree, a single root operator represents the query results, and at the bottom, the leaf operators represent scan or read operations from datasets.
Data processing begins with the reading of datasets at the bottom of the tree structure, and data is sequentially processed up the tree. A query plan can have many branches, and each branch is processed separately until a join or other operation connects it to the rest of the tree.
Phases
A query plan is composed of query phases (also called major fragments), and each phase defines a series of operations that are running in parallel. A query phase is depicted by the same colored boxes that are grouped together in a visual profile.
Within the query phases are multiple, single-threaded instances (also called minor fragments) running in parallel. Each thread is processing a different set of data through the same series of operations, and this data is exchanged from one phase to another. The number of threads for each operator can be found in the Details section (right panel) of a visual profile.
Using Visual Profiles
To navigate to the visual profile for a job:
- Click
 in the side navigation bar.
in the side navigation bar. - On the Jobs page, click a job that you would like to see the visual profile for.
- At the top of the next page, click the Visual Profile tab to open.
The main components of a visual profile are shown below:
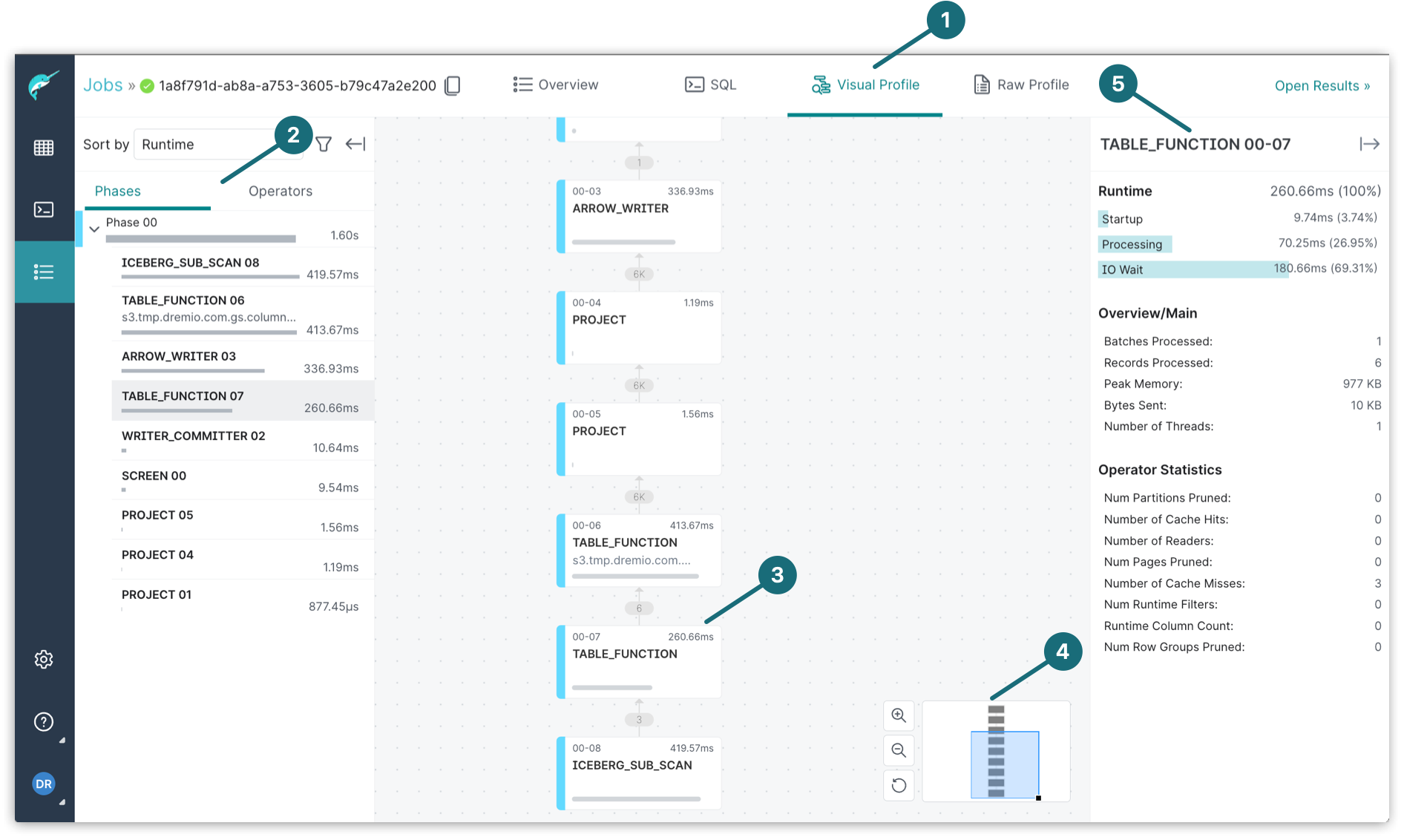
| Location | Description |
|---|---|
| 1 | The Visual Profile tab shows a visual representation of a query profile. |
| 2 | The left panel is where you can view the phases of the query execution or single operators, sorting them by runtime, total memory used, or records produced. Operators of the same color are within the same phase. Clicking the Collapse  hides the left panel from view. hides the left panel from view. |
| 3 | The tree graph allows you to select an operator and find out where it is in relation to the rest of the query plan. |
| 4 | The zoom controls the size of the tree graph so it's easier for you to view. |
| 5 | The right panel shows the details and statistics about the selected operator. Clicking the Collapse  hides the right panel from view. hides the right panel from view. |
Benefits of Visual Profiles
By examining a visual profile for a job, you can:
- Explore a view of an entire query plan, including:
- The execution phases and their operators
- A summary of processing times across all query phases, including total runtime and which phase took the most time
- Data volumes processed and transmitted between operators and phases
- Physical data movement over the network
- The order and relationship between operators
- Identify the most expensive operators by:
- Execution time
- Memory consumption
- Number of rows processed
- Explore statistics for individual operators, including:
- Processing and wait times
- Memory issues, where specific parts of SQL execution require more memory than what is available, usually the result of a high cardinality aggregation or join operation
- Slow external source, which is the query primarily waiting for an external source to return data
- Spilling for a specific operation causing a slowdown
- Data volume handled by the operator, both entering and exiting, helping you to:
- Identify exploding joins, where the result of a join operation significantly increased the data volume to be processed beyond the initial size of the tables selected
- Spot insufficient pruning for very large datasets, where too much data is returned from the scan operations to be processed, and additional or more effective filters are needed to prune data prior to processing, including partition, row group pruning, and pushdown filtering
- Spot insufficient predicate pushdown, where a query returned a large amount of data from a relational-database source due to insufficient pushdown applied
- Processing skew, which occurs when the majority of processing is performed on a small number of threads and the poor data distribution causes most threads to lack data to process
- Processing and wait times
- Review information that could help identify the root cause of performance issues, including:
- High CPU wait times that indicate issues with infrastructure capacity or workload management
- Slow response times from BI tools
- Slow response times from external data sources
- Sub-optimal data formats or file structures in your data lake
- Sub-optimal cache utilization
Use Cases
Improving the Performance of Queries
You may notice that a query is taking more time than expected and want to know if something can be done to reduce the execution time. By viewing its visual profile, you can, for example, quickly find the operators with the highest processing times.
You might decide to try making simple adjustments to cause Dremio to choose a different plan. Some of the possible adjustments include:
- Adding a filter on a partition column to reduce the amount of data scanned
- Changing join logic to avoid expanding joins (which return more rows than either of the inputs) or nested-loop joins
- Creating a Reflection to avoid some of processing-intensive work done by the query
Reducing Query-Execution Costs
If you are an administrator, you may be interested in tuning the system as a whole to support higher concurrency and lower resource usage across the system, because you want to identify the most expensive queries in the system and and then see what can be done to lower the cost of these queries. Such an investigation is often important even if individual users are happy with the performance of their own queries.
On the Jobs page, you can use the columns to find the queries with the highest cost, greatest number of rows scanned, and more. You can then study the visual profiles for these queries, identifying system or data problems, and mismatches between how data is stored and how these queries retrieve it. You can try repartitioning data, modifying data types, sorting, creating views, creating Reflections, and other changes.