Deploying Dremio with Hadoop
This topic describes how to deploy Dremio on Hadoop in YARN deployment mode.
Architecture
In YARN Deployment mode, Dremio integrates with YARN ResourceManager to secure compute resources in a shared multi-tenant environment. The integration enables enterprises to more easily deploy Dremio on a Hadoop cluster, including the ability to elastically expand and shrink the execution resources. The following diagram illustrates the high-level deployment architecture of Dremio on a Hadoop cluster.
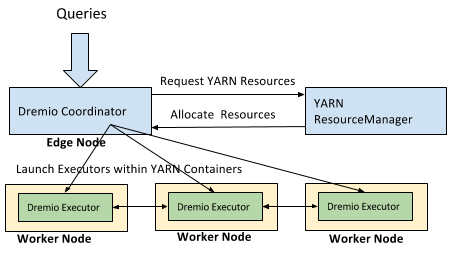
Key components of the overall architecture:
- Dremio Coordinator should be deployed on the edge node.
- Dremio Coordinator is subsequently configured, via the Dremio UI, to launch Dremio Executors in YARN containers. The number of Executors and the resources allocated to them can be managed through the Dremio UI. See system requirements for resource needs of each node type.
- It is recommended that a dedicated YARN queue be set up for the Dremio Executors in order to avoid resource conflicts.
- Dremio Coordinators and Executors are configured to use HDFS volumes for the cache and spill directories.
- Dremio implements a watchdog to watch Dremio processes and provides HTTP health checks to kill executor processes that do not shutdown cleanly.
Step 1: Hadoop-specific Requirements
Please refer to System Requirements for base requirements. The following are additional requirements for YARN (Hadoop) deployments.
Network
| Purpose | Port | From | To |
|---|---|---|---|
| ZooKeeper (External ) | 2181 | Dremio nodes | ZK |
| Namenode | 8020 | Coordinators | Namenode |
| DataNodes | 50010 | Dremio nodes | Data nodes |
| YARN ResourceManager | 8032 | Coordinators | YARN RM |
Hadoop
You must set up the following items for deployment:
- A service user (for example,
dremio) that owns the Dremio process. This user must be present on the edge and cluster nodes. - Dremio user must be granted read privileges for HDFS directories that is queried directly or that map to Hive tables. This can also be configured using groups in Sentry or Ranger.
- Create HDFS home directory for the Dremio user. This is used for storing Dremio's distributed cache.
- Grant Dremio service user the privilege to impersonate the end user. For more information about configuring Hadoop impersonation, see the Hadoop Proxy user - Superusers Acting On Behalf Of Other Users topic.
- When you have Kerberos authentication enabled, the short name of the configured principal for Dremio must match the Unix username
of the user running the Dremio daemon. For example, with default mapping for principal to short name, if Dremio's principal
is
[email protected], the UNIX user running Dremio must bedremio.
Sample Settings for Impersonating the End User
The following is a sample core-site.xml entry for granting Dremio service user the privilege to impersonate the end user:
Sample settings for impersonating end user <property>
<name>hadoop.proxyuser.dremio.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.dremio.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.dremio.users</name>
<value>*</value>
</property>
Sample Settings for Job Submission Privileges
The following sample fair-scheduler.xml entry creates a dedicated YARN queue for Dremio executor nodes with job submission privileges
for the user running Dremio. This sample is for Fair Scheduler with a fair-scheduler.xml entry:
<allocations>
<queue name="dremio">
<minResources>1000000 mb,100 vcores,0 disks</minResources>
<maxResources>1000000 mb,100 vcores,0 disks</maxResources>
<schedulingPolicy>fair</schedulingPolicy>
</queue>
</allocations>
The minResources and maxResources settings are global;
they specify how much cluster capacity is allocated to queue.
For example, if you need 10 executors at 100GB each, the configuration values should be 1TB.
For more Hadoop information, see
Capacity Scheduler and
Fair Scheduler.
Run the following for queue configuration changes to take affect:
sudo -u yarn yarn rmadmin -refreshQueues
Kerberos
If connecting to a cluster with Kerberos:
- Create a Kerberos principal for the Dremio user
- Generate a Keytab file for the Dremio Kerberos principal
WANdisco
When working with WANdisco-based deployments, you need to do the following before starting Dremio coordinators and deploying executor nodes on YARN.
- Link the WANdisco-specific client JARs on coordinator nodes under the
dremio/jars/3rdpartydirectory.
For example, assuming that the WANdisco-specific client JARs are located under /opt/wandisco/fusion/client/,
then you would link the JARs on the coordinator nodes with the following:
ln -s /opt/wandisco/fusion/client/lib/* /opt/dremio/jars/3rdparty
Step 2: Install and Configure Dremio
This step involved installing Dremio, copying over site .xml files, and configuring Dremio on each node in your cluster.
Installing Dremio
Installation should be done as the dremio user. For more information, see Installing and Upgrading via RPM or Installing and Upgrading via Tarball.
Copying Site XML files
Before proceeding with configuration,
copy your core-site.xml, hdfs-site.xml and yarn-site.xml (typically under /etc/hadoop/conf) files
into Dremio's conf directory on the coordinator node(s).
For Hortonworks deployments, make the following changes in yarn-site.xml that you've copied over to Dremio's conf file:
- Completely remove the
yarn.client.failover-proxy-providerproperty. - Set the
yarn.timeline-service.enabledproperty tofalse.
Configuring Dremio
When referring to a Dremio coordinator, the configuration is for a main coordinator role.
Configuring Dremio via dremio.conf
The following properties must be reviewed and or modified.
-
Specify a main coordinator role for the coordinator node:
Specify main coordinator roleservices: {
coordinator.enabled: true,
coordinator.master.enabled: true,
executor.enabled: false
} -
Specify a local metadata location that only exists on the coordinator node:
Specify local metadata locationpaths: {
local: "/var/lib/dremio"
...
} -
Specify a distributed cache location for all nodes using the dedicated HDFS directory that you created:
Specify distributed cache location for all nodespaths: {
...
dist: "hdfs://<NAMENODE_HOST>:8020/path"
# If Name Node HA is enabled, 'fs.defaultFS' should be used
# instead of the active name node IP or host when specifying
# distributed storage path. 'fs.defaultFS' value can be found
# in 'core-site.xml'. (e.g. <value_for_fs_defaultFS>/path)
} -
Specify the Hadoop ZooKeeper for coordination:
Specify Hadoop ZooKeeperzookeeper: "<ZOOKEEPER_HOST_1>:2181,<ZOOKEEPER_HOST_2>:2181"
services.coordinator.master.embedded-zookeeper.enabled: false -
If using Kerberos, specify the principal name and keytab file location:
Specify princpal name and keytab file location for Kerberosservices.kerberos: {
principal: "[email protected]", # principal name must be generic and not tied to any host.
keytab.file.path: "/path/to/keytab/file"
}
Configuring Dremio via core-site.xml
If using Kerberos, create a core-site.xml file under Dremio's configuration directory
(same directory as dremio.conf) and include the following properties:
<property>
<name>hadoop.security.authentication</name>
<value>kerberos</value>
</property>
Starting the Dremio Daemon
Once configuration is completed, you can start the Dremio Coordinator daemon with the command:
Start Dremio Coordinator daemon$ sudo service dremio start
Accessing the Dremio UI
Open a browser and navigate to http://<COORDINATOR_NODE>:9047. UI flow will then walk you through creating the first admin user.
Step 3: Deploy Dremio Executors on YARN
Once the Dremio Coordinator is successfully deployed:
-
Navigate to the UI > Admin > Provisioning section.
-
Select YARN and then select your Hadoop distribution and configuration. ** Dremio recommends having only one worker (YARN container) per node.**
-
Configure
Resource ManagerandNameNode.Resource Managerneeds to be specified as a hostname or IP address (e.g.192.168.0.1) andNameNodeneeds to be specified with the protocol and port (e.g.hdfs://192.168.0.2:8020) -
Configure spill directories. Dremio recommends pointing this to the
Configure spill directoriesusercachedirectory under the path specified inyarn.nodemanager.local-dirs.file:///data1/hadoop/yarn/local/usercache/<DREMIO_SERVICE_USER>/
file:///data2/hadoop/yarn/local/usercache/<DREMIO_SERVICE_USER>/ -
Monitor and manage YARN executor nodes.
Step 4: (Optional) Configuring for Name Node HA and Resource Manager HA
This step is optional, depending on whether you enabled Name and Resource Manager for high availability.
Configure Name Node HA
If Name Node HA is enabled, fs.defaultFS value should be used as the NameNode value
instead of the active name node IP or host when configuring provisioning in Dremio UI.
Similarly, when specifying distributed storage (paths.dist in dremio.conf),
path should be specific using fs.defaultFS value instead of the active name node. (e.g. <value_for_fs_defaultFS>/path)
The fs.defaultFS value can be found in core-site.xml
Configuring Resource Manager HA
If Resource Manager HA is enabled, yarn.resourcemanager.cluster-id should be used as
the Resource Manager value instead of the active resource manager IP or host when configuring provisioning in Dremio UI.
The yarn.resourcemanager.cluster-id value can be found in yarn-site.xml.
Sample dremio.conf Configuration
The following is a sample dremio.conf configuration for a coordinator node.
dremio.conf configuration
services: {
coordinator.enabled: true,
coordinator.master.enabled: true,
executor.enabled: false,
}
paths: {
# the local path for dremio to store data.
local: "/var/lib/dremio"
# the distributed path Dremio data including job results, downloads, uploads, etc
dist: "hdfs://<NAMENODE_HOST>:8020/path"
# If Name Node HA is enabled, 'fs.defaultFS' should be used
# instead of the active name node IP or host when specifying
# distributed storage path. 'fs.defaultFS' value can be found
# in 'core-site.xml'. (e.g. <value_for_fs_defaultFS>/path)
}
zookeeper: "<ZOOKEEPER_HOST>:2181"
# optional
services.kerberos: {
principal: "[email protected]", # principal name must be generic and not tied to any host.
keytab.file.path: "/path/to/keytab/file"
}
Troubleshooting
In YARN deployments using Ranger, access is denied when attempting to query a data source configured to Ranger authorization and Dremio logs a "FileNotFoundException */xasecure-audit.xml (No such file or directory)" error. This behavior is triggered within the Ranger plugin libraries when hdfs-site.xml or hive-site.xml are present in the Dremio configuration path.
To fix this environment issue, rename the ranger-hive-audit.xml configuration file generated by the Ranger Hive plugin installer to xasecure-audit.xml and copy it to the Dremio configuration path on all coordinator nodes.