Architecture
Dremio is a data lakehouse platform that facilitates high-performance, self-service analytics on large datasets. Dremio enables direct querying of data stored in various formats across multiple sources, including cloud storage, relational databases, and NoSQL systems.
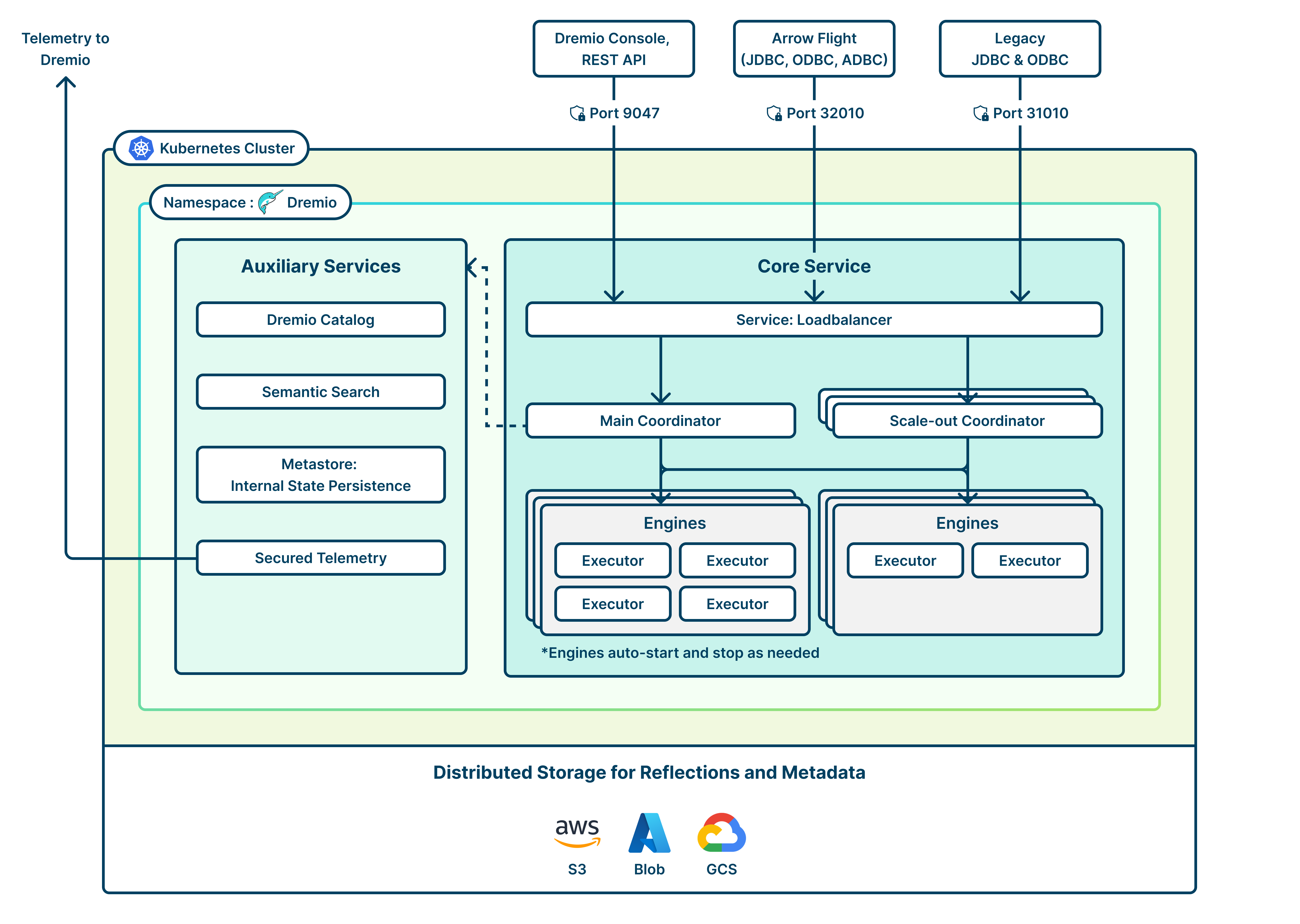
The architecture of Dremio is built around its columnar execution engine, Apache Arrow-based in-memory processing, and data Reflections that optimize query performance. Dremio integrates seamlessly with BI tools, supports SQL-based querying, and employs a distributed execution model to enhance scalability.
Namespace
Namespaces are typically used in environments where many users are spread across multiple teams or projects. In Kubernetes, a namespace provides a mechanism for isolating groups of resources within a single cluster.
Core Services
Dremio’s core services are fundamental components that enable its high-performance, distributed query engine and data lakehouse capabilities: coordinators and engines.
Main Coordinator
The main coordinator manages query planning, execution coordination, and cluster resource allocation. It oversees the system’s workload by distributing queries to executor nodes, creating and optimizing query plans, and maintaining metadata for efficient data access.
Key responsibilities of the main coordinator include:
-
Query Planning and Optimization: Query planning converts SQL queries into optimized execution plans using cost-based optimization techniques.
-
Job Management: Schedules and monitors query execution across the cluster
-
Metadata Management: Dremio leverages metadata to improve data visibility, plan and accelerate queries, and facilitate seamless integration across data sources. Dremio maintains metadata describing each data source's structure, content, and format to ensure accuracy and speed in query planning and the resulting query execution. Metadata also plays a key role in user services, such as data lineage, governance, quality, and discovery.
-
Client connections: Dremio supports a broad range of clients including its web-based Console and clients connecting over Arrow Flight, JDBC, ODBC, and Dremio REST.
Scale-Out Coordinators
A scale-out coordinator provides additional capacity for query planning. When multiple coordinators are deployed, a load balancer service automatically routes incoming queries to an available coordinator in a round-robin manner.
By distributing the query planning workload, scale-out coordinators prevent bottlenecks and improve overall query performance, especially during peak loads. Scale-out coordinators also use Dremio to scale to support many users and queries concurrently.
Load Balancer
In a Kubernetes deployment, a load balancer can be installed in several approaches, such as a cloud-native service or an Ingress controller. The load balancer efficiently distributes incoming queries across multiple coordinator pods to optimize performance and ensure high availability. Additionally, session persistence and failover mechanisms help maintain stability by redirecting requests to healthy coordinators in case of failures.
Engines
Engines are responsible for query execution. Each engine comprises one or more executors performing queries and DML operations. Executors run the query execution plan created by the coordinator and transit data between themselves to serve queries.
Workload Management
Engines are defined by their size, such as the number and size of each executor, and other properties to optimize the engine for your query load. Engines can be started, stopped, and resized at any time.
Dremio allows you to configure the workloads running on each engine. Isolating workloads on their engines will enable you to manage the performance and cost for each workload, target compute resources to the most important workloads, and respond to changing priorities.
Cloud Columnar Cache
The Dremio Cloud Columnar Cache is a high-performance, disk-based caching layer located on each executor, designed to accelerate query performance when working with remote or cloud-based storage like Amazon S3 or Azure Data Lake. It automatically stores frequently accessed data in Dremio’s optimized columnar format, allowing future queries to read from the local cache instead of repeatedly fetching data from slower, more costly cloud storage. This results in faster query execution, reduced latency, and lower cloud storage egress costs. The cache is managed transparently by Dremio and uses an LRU (least recently used) eviction policy to stay within configured storage limits.
Auxiliary Services
Auxiliary services on Kubernetes support the core query execution engine by handling metadata storage, telemetry, and AI-enabled semantic search tasks. Kubernetes runs these services as separate pods, ensuring they can be independently configured, scaled, and managed for efficient resource allocation and high availability.
Open Catalog
Dremio's integrated Iceberg catalog is built on Apache Iceberg to provide advanced data lakehouse management capabilities. This integration allows users to leverage Iceberg features such as Data Manipulation Language (DML) operations and data optimization techniques, including automatic compaction and table clean-up, which enhance query performance and reduce storage costs.
The Open Catalog supports interoperability with other Iceberg-compatible engines, such as Apache Spark and Flink, facilitating seamless data operations across different platforms. It also enables the management of multiple isolated domains or catalogs within an organization, each containing a hierarchical structure of tables and views. This design supports centralized governance with fine-grained access control, promoting federated ownership and secure data sharing across domains.
AI-Enabled Semantic Search
AI-enabled semantic search is an advanced feature designed to enhance data discovery and accessibility. It enables users to find datasets, tables, and metadata using natural language queries rather than relying solely on structured SQL-based searches. This feature significantly improves the efficiency of data exploration, enabling analysts and data engineers to find the right datasets faster without needing deep knowledge of underlying structures.
Metastore
A metastore is a centralized repository for metadata such as schemas, tables, partitions, and other structural information about datasets, enabling efficient data discovery, access, and management across a distributed environment. This metastore is distinct from the Open Catalog and other metastores, such as a Hive metastore that contain data about an individual integrated data source.
Secured Telemetry
Dremio clusters automatically transmit telemetry data to Dremio's corporate endpoint. This data includes application metrics, such as the number of queries, sources, and views; Java metrics, such as the number of active threads; and container metrics, such as CPU and memory utilization. This telemetry provides valuable insights into system performance and health, enabling Dremio to enhance product stability and support. No customer content or business data is transmitted.
Distributed Storage
Dremio’s distributed store uses scalable and fault-tolerant storage for Dremio Reflections, job results, downloads, upload data, and scratch data. By leveraging object stores like Amazon S3, Azure Data Lake Storage (ADLS), and Google Cloud Storage, as well as distributed file systems like HDFS, Dremio ensures durability and accessibility across multiple nodes in a cluster. Additionally, the distributed store plays a key role in caching frequently accessed data, reducing query latency and enhancing the system's overall responsiveness.
High Availability
Kubernetes automatic failover and scaling achieve high availability in Dremio on Kubernetes. If any Kubernetes pods go down for any reason, Kubernetes brings up another pod to replace them. The Dremio main coordinator and secondary-coordinator pods are each a StatefulSet. If the main coordinator pod goes down, it recovers with the associated persistent volume and Dremio metadata preserved. Secondary coordinator pods do not have a persistent volume. The Dremio executor pods are also a StatefulSet, with an associated persistent volume. If an executor pod goes down, it recovers with the associated persistent volume and data preserved.